文 | 硅谷 101
英伟达 2025 年 3 月 18 日的 GTC 大会看似平淡,但魔鬼和惊喜都藏在细节中。
英伟达创始人兼 CEO 黄仁勋发布的各项更新,包括芯片路线图,此前已经被市场预期消化。在本次 GTC 之前,英伟达股价已经承压多时,华尔街对接下来 AI 芯片需求的可持续性存在怀疑。而在整场演讲中,黄仁勋也试图打消外界的疑虑,但在当天,英伟达股价仍然下跌 3.3%。

我们刚听完黄仁勋的 Keynote 演讲之后,第一反应也觉得好像不如去年那么震撼和精彩,再加上演讲中间 PPT 和流程还出现了各种小错误,让整个演讲不如去年那么完美。
但结束之后我们跟一些机构投资人和芯片从业者深聊的时候发现,很多人对英伟达的发展路线和布局还是非常看好,认为英伟达正继续和竞争对手们甩开差距,虽然在宏观层面上股价确实在近期受到多方面因素承压。

这篇文章我们就和嘉宾们一起来聊聊在此次 GTC 上的观察,并试图来回答以下几个问题:
1. 英伟达如何继续扩宽它的护城河?
2. 在 AI 市场迈入 「推理 inferencing」 阶段,英伟达还能是市场上独占鳌头的赢家吗?AMD、Groq、ASIC 芯片还有谷歌的 TPU 等等玩家有机会翻盘吗?
3. 英伟达如何布局全市场生态,让所谓的 「每个人都成为赢家」?
4. 对于目前承压的股价,英伟达的下一个故事是什么?是机器人、还是是量子计算呢?
01 横向拓展与纵向拓展
黄仁勋在 Keynote 演讲中数次强调:英伟达不是单张 GPU 芯片的叙事,而是所谓 「Scale Up and Scale Out」 更宏大的叙事。
黄仁勋说的 Scale Up 指的是 「纵向扩展」,也就是通过 NVLink 通信互联技术将单个系统的功能推到极致。

而 Scale Out 指的是 「横向扩展」,也就是通过这次发布的硅光技术 CPO(Co-packaged Optics,光电一体封装交换机) 等革命性技术更新,来进一步实现数据中心 (data center) 的巨大算力集群的快速扩张和提效。

而在 AI 迈入 「推理」 时代而对算力愈加渴望之际,英伟达 「纵向」 和 「横向」 的扩展将打造新一代 AI 强大的算力生态和架构,这就是黄仁勋想讲的新故事。
任扬
济容投资联合创始人:
老黄几年前其实也在反复强调这个概念:以后计算单元不是 GPU,甚至不是服务器,而是整个数据中心是一个计算单元。这是黄仁勋一直在试图去推动的方向吧。
Chapter 1.1 Scale Up
在讲纵向扩展前,我们先聊聊黄仁勋公布的之后几代芯片的路线图。
在 Keynote 中,黄仁勋给出了非常清晰的英伟达长期路线图,包括从当前的 Blackwell 到未来的 Blackwell Ultra、Vera Rubin、Rubin Ultra,最终到 2028 年的 Feynman 架构。
每一代更新的芯片架构名字最后的数字,代表的是 GPU 的芯片数量,而每一个架构代表的是一个机架的整个性能。这个新命名方式也印证了黄仁勋想强调的叙事,已经从单个 GPU 变成了数据中心的算力集群系统。

2025 年下半年出货的 Blackwell Ultra NVL72 连接了 72 块 Blackwell Ultra GPU,它的性能提升是前代 GB200 的 1.5 倍 (这里要注意一下,黄仁勋在 Keynote 中又重新定义了 「黄氏算法」:从 Rubin 开始,GPU 数量是根据 「封装中的 GPU 数量」,而不是 「封装数量」 来计算的;所以按新的定义,Blackwell Ultra NVL72 算是有 144 个 GPU)。
以天文学家 Vera Rubin 命名的新一代 GPU 将于 2026 年下半年推出。Vera Rubin NVLink144 的性能将是 Blackwell Ultra(GB300)NVL72 的 3.3 倍。
英伟达预计 Vera Rubin 之后,下一代 Rubin Ultra NVL576 将于 2027 年下半年推出,其性能将是 Blackwell Ultra(GB300)NVL72 的 14 倍。

Rubin 之后的架构代号为 「Feynman」,以理论物理学家查德・费曼命名,这已经是 2028 年之后的故事了。
芯片从业人士告诉我们,英伟达的路线图和性能提升幅度并没有出乎外界的预期范围,但黄仁勋传达出的信号仍然非常积极,这就是:英伟达正在以及在未来几年都会稳健地给客户交付更好性能的产品。
David Xiao
CASPA 主席
资深芯片从业者
ZFLOW AI 创始人兼 CEO:
其实在我们芯片行业,以英伟达这样的节奏发布产品,已经是执行力非常强了。一般芯片公司从一款产品到下一款产品,芯片研发可能需要两年时间,再加上软件适配,可能就需要 3 到 4 年才能推出下一代芯片和系统,所以英伟达的这个节奏已经非常厉害。
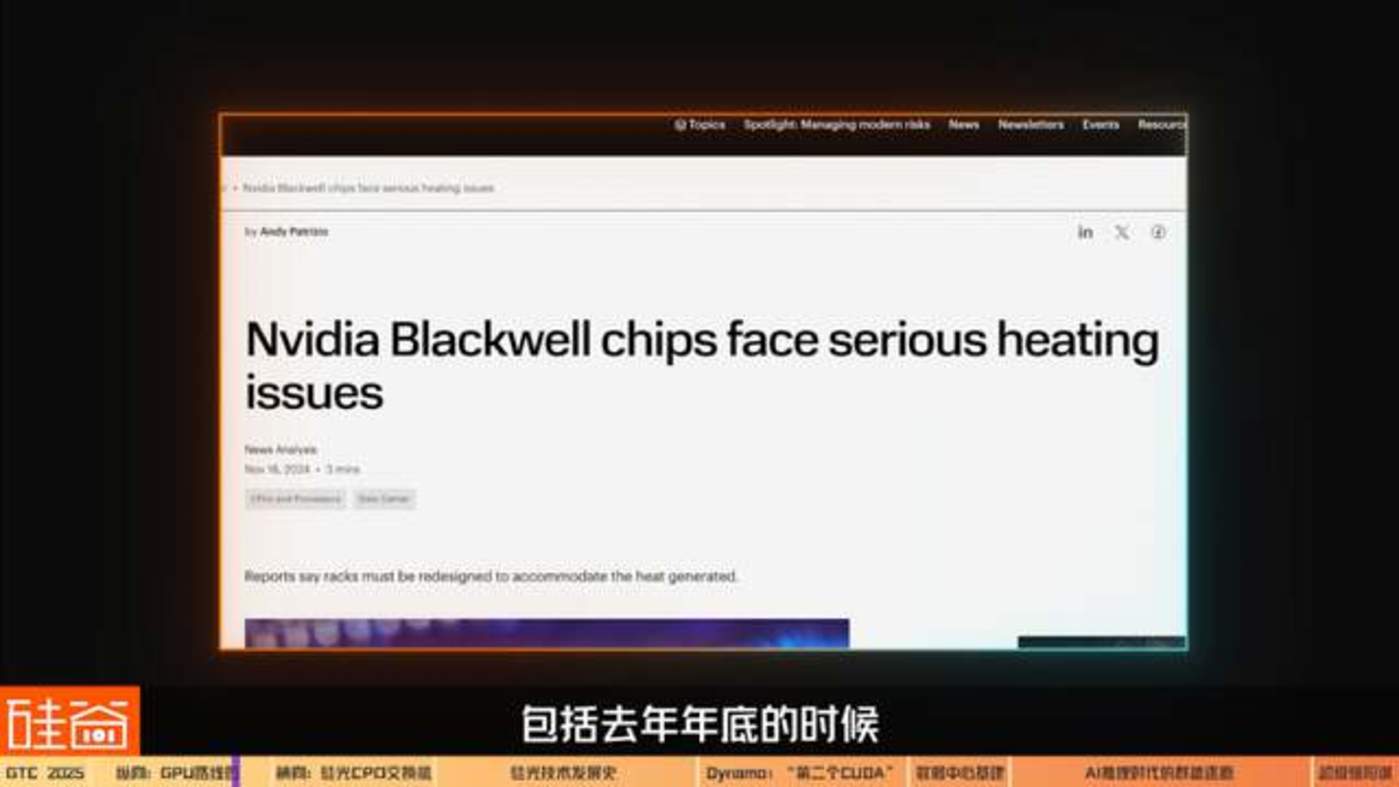
但这也会让公众的期望更高。比如去年年底的时候,Blackwell 出现了散热和良率的问题,股市上的反应是非常强烈的。但对我们业内人士来说,这些问题是非常正常的。重新 mask tap out(掩膜流片),再修正就可以了。
任扬
济容投资联合创始人:
我觉得不管从产品的规划、定义,到最后的落地执行,英伟达都是非常稳健、且领先对手的。但是如果和投资人的预期相比,确实没有惊喜,也没有意外。
以上就是黄仁勋所说的 Scale Up(纵向拓展) 的部分,也是嘉宾口中的与预期相同、没有惊喜的部分。接下来我们聊聊让大家惊喜的部分,也就是 Scale Out(横向扩展) 的布局。
Chapter 1.2 Scale Out
最能表现黄仁勋对 「规模扩展」 野心的,是采用集成硅光技术的 NVIDIA CPO(Co-packaged Optics,光电一体封装交换机)。

虽然老黄在演讲中展示的时候这些黄色的线被缠在了一起,弄了好久才弄开,但也是挺有话题度的,让大家对这几根线更好奇了。
接下来我们聊聊,这几根线是怎么运作的?如何能让英伟达的数据中心纵向扩展呢?

David Xiao
CASPA 主席
资深芯片从业者
ZFLOW AI 创始人兼 CEO:
现在所有的 Blackwell 的机器,还是基于铜的互联 (Copper),之后会转向光的互联。

按照英伟达的说法,CPO 交换机的创新技术,是将插拔式的光模块替换为与 ASIC(专用集成电路) 一体化封装的硅光器件。
与传统网络相比,可将现有能效提高 3.5 倍,网络可靠性提高 10 倍,部署时间缩短 1.3 倍。这能极大程度增强英伟达数据中心的互联性能,对于实现未来百万级 GPU 的 AI 工厂的大规模部署来说至关重要。

匿名对话
早期 CPO 光学科研人员:
OpenAI 去年训练 4o 的时候经常会训练失败,因为当时的 Frontier model(前沿模型) 已经基本穷尽了大部分的数据,所以训练失败的次数很多。训练 GPT-5 失败的次数也非常多,因为失败的次数更多了,所以做需要做更多实验,而且每次实验的时间要尽可能短,公司是不能忍受一个实验做两个礼拜没消息的。如何能缩短时间?那就是提高通讯的速度。

除了速度快之外,CPO 交换机也能在能耗和价格上带来很多成本的节省。在 GTC 现场,英伟达的工作人员展示了 CPO 实物是如何运作的。
Brian Sparks
英伟达工作人员:
这就是我们的新产品:Quantum-X 光子交换机。 这款交换机采用了 ASIC(专用集成电路),也是我们首次能够实现硅光子技术的 CPO(光电混合封装)。过去需要一个光纤收发器用于连接网卡。但现在,光信号可以直接进入交换机的接口,不再需要光纤收发器。这样做有两个好处:首先降低了成本,因为光纤收发器价格相当昂贵;其次减少了功耗,因为传统光纤收发器大约消耗 30 到 33 瓦的功率,而我们现在能够将功耗降低到 9 瓦。

我们的对话嘉宾认为,训练侧客户在意的是时间,推理侧客户在意的是成本。而 CPO 技术能在一定程度上同时这两种需求,提高训练与推理的效率。
孙田浩
美国二级市场投资人
某新加坡联合家办资深分析师:
你如果只有一个芯片,把它打造得再厉害也是没有用的。本质原因是我们现在做推理、训练,都是用几万个卡在一起的集群,比如 Grok 可能就一下就用 20 万个卡一起训练。重要的是怎么能让几万个、十万个 芯片高效地协同运作。在这个互联领域英伟达又再一次地领先了全球,因为它有 CPO,它的机柜上有各种各样的新花样。所以我觉得从长线来看,英伟达在推理集群领域的优势也是更明显的。
Brian Sparks
英伟达工作人员:
当进行推理时需要大量的计算资源,需要更多的计算能力,因此网络需要具备尽可能高的带宽,能够在每个端口上提供更多的性能,同时保持极低的延迟。通过去掉光纤收发器,就能离这个目标更进一步,并能减少功耗。

Chapter 1.3 CPU 发展史和早期八卦
关于 CPO,我们在对话期间还挖出一点点小八卦:黄仁勋在 Keynote 期间说 CPO 是他们发明的,但光学工程师们可能会有一些不同的意见。
我们对话了非常早期的硅光技术 CPO 的研究者和业内从业者,他们表示,CPO 这个技术从 2000 年左右在业界就已经开始研究了,而最开始主导这个技术的是英特尔。
匿名对话
早期 CPO 光学科研人员:
当时我们提出来的这个技术叫做 Monolistic Integrated Phontonic IC(单片集成光子集成电路),那时候还不叫 Co-packaged Optics 。当时做这个事情是因为英特尔对 Big Data(大数据) 很感兴趣。

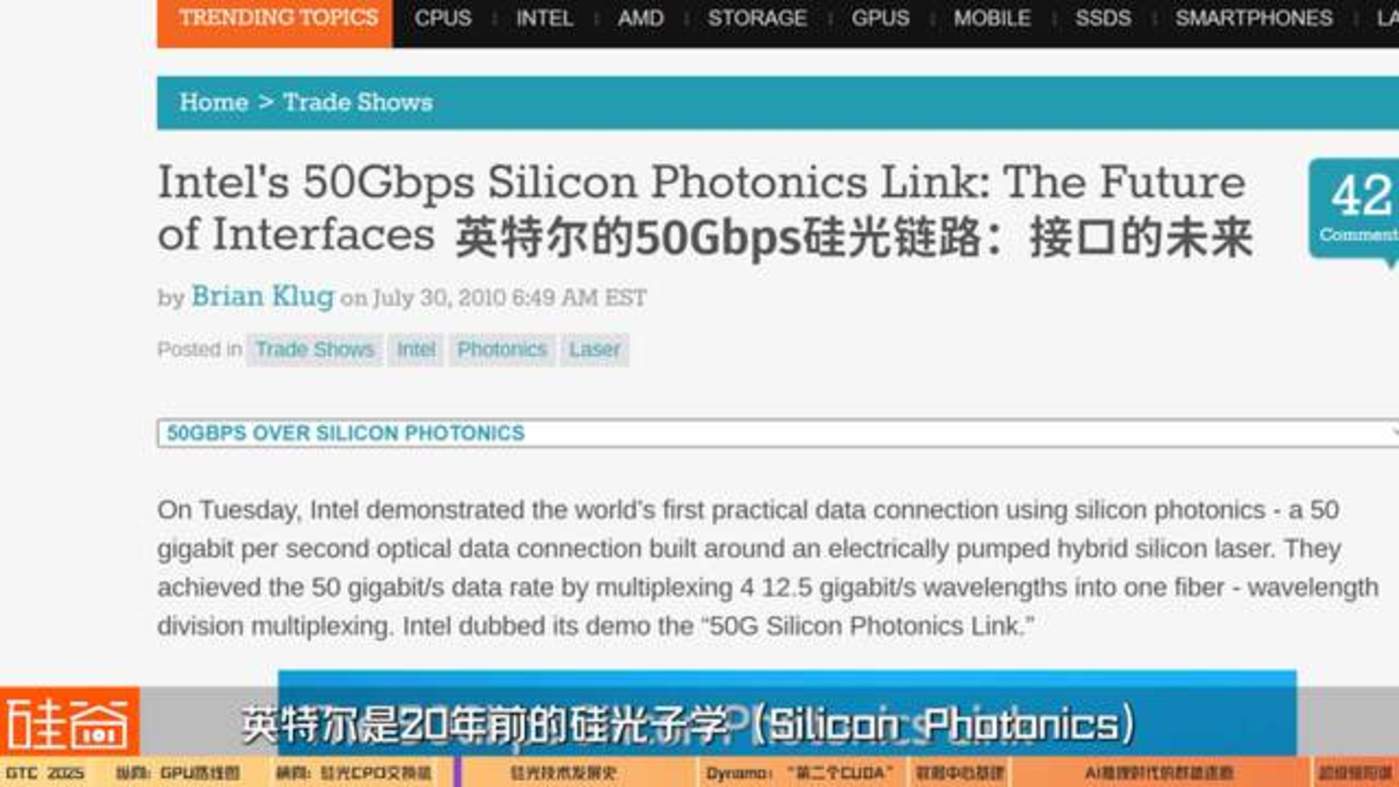
这位资深的光学研究者告诉我们,大数据业务的驱动下,英特尔是 20 年前的硅光子学 (Silicon Photonics) 最大的研究支持机构。而之后发展出的 CPO(Co-packaged optics) 技术最早开始研发是为了解决光电系统短距离通信,也是光纤通信研究发展的必然结果。
而在行业发展过程中,除了英特尔,其它小型企业也在尝试研发这项技术。但硅光子学技术的研发非常耗钱耗力,需要先有市场需求,才能倒逼技术研发。
以上是 Nathan 评测的一部分节选,想看完整版的观众可以收看硅谷 101 视频或 Nathan 的微信视频号 「硅谷 AI 领航」。
匿名对话
早期 CPO 光学科研人员:
最开始的时候,CPO 应用是大数据,就是数据中心之间的通信。但数据中心之间的通信不需要那么高的码率,100G 之内都不需要 CPO。直到 2012 年,当时 Apache Spark(开源集群运算框架) 出现了,而且 Snowflake 开始快速发展,在这一年数据库开始上云了。这就意味着大量数据存在一个地方,而读取和使用在另外一个地方,你需要做 query(查询),数据的移动就变得非常得复杂,量也变得非常大。这时 100G 在数据中心之间的沟通已经不够用了,所以从 2012 年开始,Google 提升到 400G,到 2020 年疫情之前提到了 800G。

如果现在同样大的 connector(连接器) 要做 800G ,里面的集成度就要高很多。当集成度高了后,光纤系统设计就非常复杂。需要解决功耗、一致性等等问题。但这两个问题解决了以后,良率基本上是 0。从 100G 到 200G、 200G 到 400G、 400G 到 800G,每一代一出来良率都是 0。而研发费用是非常贵的,基本是 5 个亿以上。
以前没有新的应用就不会去研发,现在有了新的应用,数据仓库出现了,所以开始研发。在 400G 发展到 800G 的时候,Meta 和 Google 的报告中已经开始广泛地使用 POP(package on package) 和 PIP(package in package) 这两个词,其实跟今天 Co-package 的概念基本上很接近了。

为什么硅光子技术的良率会这么低,需要花费的研发费用又这么高呢?
Cathy
光学工程师:
我们人的头发的尺寸大概是一个 0.01 平方毫米,已经是一个非常小的尺寸了。但在现实使用的 Silicon Photonics Engine(硅光子引擎) 里面,Microring resonator(微环谐振器) 的尺寸比人的头发还要再小十倍。
在制作的时候,哪怕是用非常先进的工艺,也很容易造成纳米级别的误差。而且即使是纳米级别的误差,都会使得通过的光的波长有所误差。所以稍微一个不留神,就会导致本来该通过的光完全彻底通不过。
除此之外,我们需要精细到纳米级别的加工精度的控制,降到一个纳米基度的级别是非常困难的一件事情。
另外因为需要控制温度,所以每一个 Ring resonator(环形谐振器) 都有自己的一个 Heating Pad(加热垫)。然后加热垫连上一个精密的、有 feedback(反馈) 的温度调控。而同时温度调控又是一个时间的参数,因为光的通过速度非常快,所以需要一个非常精确、非常智能的温度控制系统。而且每一个小的 Micro resonator(微型谐振器) 都需要这样去调控,可以想象在一整个 package(套件) 里面有这么多的激光器,就需要非常复杂的一个温度调控的算法。最终这一切加起来导致的效果就是,硅基光子的良率非常的低。

一位多年的从业者 Mehdi Asghari 和我提到过一句话:在电子制造之中,你不用提良率,因为良率都非常高,是 99.999…(无数个 9),只有良率高了大家才能赚钱。但在硅基光子的行业中也不用提良率,因为大家都知道良率非常低,稍微不小心就会导致良率崩盘。正是因为需要各种精确的控制,会让良率非常低,这也导致了硅基光子的成本下不来。所以必须有个行业,既需要快速、精确的控制,又能接受高成本,才能让硅基光子学发展起来。
陈茜
硅谷 101 视频主理人:
后来是怎么把良率给提上去的呢?
Cathy
光学工程师:
行业一点一点的磨合。英特尔在 2000 年就开始做了,在这方面像行业的先驱。虽然老黄在硅基光子学并不是最早的,但是老黄为大家找到了非常好的应用,能让这个技术应用在数据中心、AI 大模型里面,有了实在的用武之地。
根据嘉宾的说法,英伟达的光学通信系统技术,来自 2019 年收购的以色列芯片厂商 Mellanox,而 Mellanox 的技术又源自于 2013 年收购硅光子公司 Kotura。
以上我们大概讲了讲 CPO 技术的发展史,和业内从业者对老黄说 「CPO 是英伟达发明的」 一点 challenge(挑战)。 也欢迎如果有硅光子产业的从业人员给我们留言说说你们对这个技术发展的八卦和故事。
不过,正是因为黄仁勋看到了 CPO 在 AI 数据中心大规模的应用,才又一次通过市场应用来支持技术研发,将这个技术带到了大众的面前。

匿名对话
早期 CPO 光学科研人员:
如果 LLM(大语言模型) 只是千亿美元级的市场的话,老黄根本就不会干这个事,因为研发太贵了。但现在 LLM 到了万亿美元级的市场,老黄就认为有市场了,就跟我之前说的 800G 数据仓库是一样的。既然 LLM 来了 (市场来了),且这是一个不违反物理定律的事情,那只要钱堆得足够多,不违反物理定律的事情都是能做成的。
虽然 CPO 技术不是英伟达独家的,很多大公司都掌握了这个技术。但我们的嘉宾认为,英伟达在内部大力推进 CPO 技术整合到生态中,将 CPO 做到竞品 roadmap(路线图) 的数倍,用快速的执行和研发效率,进一步加深了生态的护城河和壁垒。

David Xiao
CASPA 主席
资深芯片从业者
ZFLOW AI 创始人兼 CEO:
英伟达在光这块其实投入也很大,招了很多人,也从各大公司都挖了不少人,会进一步加深壁垒。
因为其实有很多做硅光的公司可以做 CPO 的 Module(模块),但是如果要跟 AI 芯片合在一起做,那一定要找这些 AI 芯片出货量最大的厂去合作。因为这里面涉及到芯片跟硅光模块 codesign(共同设计) 的问题。而英伟达是 in house(内部研发) 的话,相比其他硅光公司跟 AMD、Sarabas、Groq 合作,会有很多的 know-how(实际知识和性能) 的优势。

02 第二个 CUDA
我们再来说说英伟达在软件生态上的另外一个重要更新:Dynamo。这被我们的嘉宾认为是英伟达想在推理侧造就的 「第二个 CUDA」。
黄仁勋
英伟达创始人兼 CEO:
Blackwell NVLink72 搭配 Dynamo,使 AI 工厂的性能相比 Hopper 提升 40 倍。在未来十年,随着 AI 的横向扩展,推理将成为其最重要的工作内容之一。

黄仁勋宣布在软件方面,英伟达推出了 Nvidia Dynamo。这是一款开源的 AI 推理服务软件,被视为 Nvidia Triton 推理服务器的 「接班人」,旨在简化推理部署和扩展。而它的设计目标也很明确:以更高效和更低的成本来加速并扩展 AI 模型的推理部署。
简单来说,Dynamo 就像 AI 工厂中的 「大脑和中枢」,负责协调成百上千张 GPU 的协同工作,确保每一次 AI 模型的推理请求都能用最少的资源、最快的速度得到处理,从而让部署这些模型的企业花更少的钱去办更多的事。
一些美股分析师认为:如果说 CUDA 是英伟达最强大的软件生态护城河,那么 Dynamo 就是英伟达在推理侧想搭建的第二道护城河。

孙田浩
美国二级市场投资人
某新加坡联合家办资深分析师:
英伟达 60% 以上的护城河都来自于软件。这一次推出的 Dynamo,相当于是在大模型 AI 领域又再造了一个 CUDA。因为 Dynamo 是能给推理降本的,而且还开源了。Dynamo 早期在未来新方向的布局上和 CUDA 是一样的;从长线来说,可能英伟达能再造一个 CUDA,这对于它的在 AI 这个领域的护城河的帮助是非常强的。这是我比较看好的一个更新。
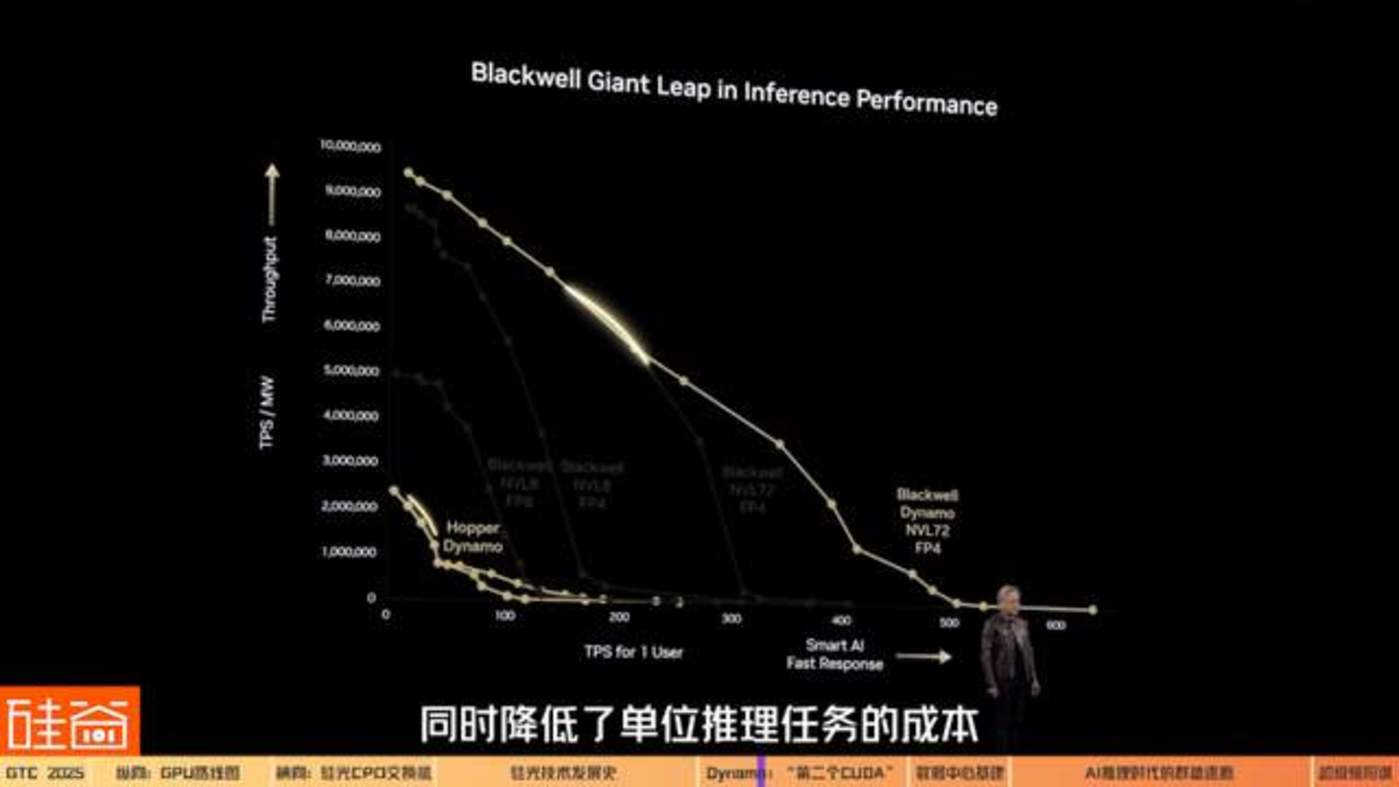
Dynamo 带来的最大亮点之一,就是大幅提升了推理性能和资源利用率,同时降低了单位推理任务的成本。
做一个类比,Dynamo 就像一家餐厅的智能调度经理,在忙时能迅速增派更多厨师 (也就是 GPU) 上灶,在闲时又让多余的厨师休息,不让人力闲置,从而做到高效又节约。
根据英伟达官网,Dynamo 包含了四项关键创新,来降低推理服务成本并改善用户体验。

1.GPU 规划器 (GPU Planner):这是一种规划引擎,可动态地添加和移除 GPU,以适应不断变化的用户需求,从而避免 GPU 配置过度或不足。这就像我们刚才说的厨房遇到就餐高峰的时候,就加派厨师人手、加开新的厨房,而客人少的时候就关掉部分厨房,Dynamo 希望确保 GPU 不闲着也不堵车,始终在最佳负载下运行。这样每一块 GPU 都被充分利用,集群整体吞吐量随之提高。
2. 智能路由器 (Smart Router):这是一个具备大语言模型 (LLM) 感知能力的路由器,它可以在大型 GPU 集群中引导请求的流向,从而最大程度减少因重复或重叠请求,而导致的代价高昂的 GPU 重复计算,释放出 GPU 资源以响应新的请求。这有点像客服中心里把老客户直接转接给之前服务过他的座席员,因为那位座席员已经有客户的记录 (缓存),可以免去重复询问,更快给出回答。而 Dynamo 正是利用这种机制,将过往推理中产生并存储在显存里的 「知识」 (KV 缓存) 在潜在的数千块 GPU 间建立索引映射,新请求来了就路由到握有相关缓存的 GPU 上。这样一来,大量重复的中间计算被省略,让 GPU 算力主要服务新的独立请求。
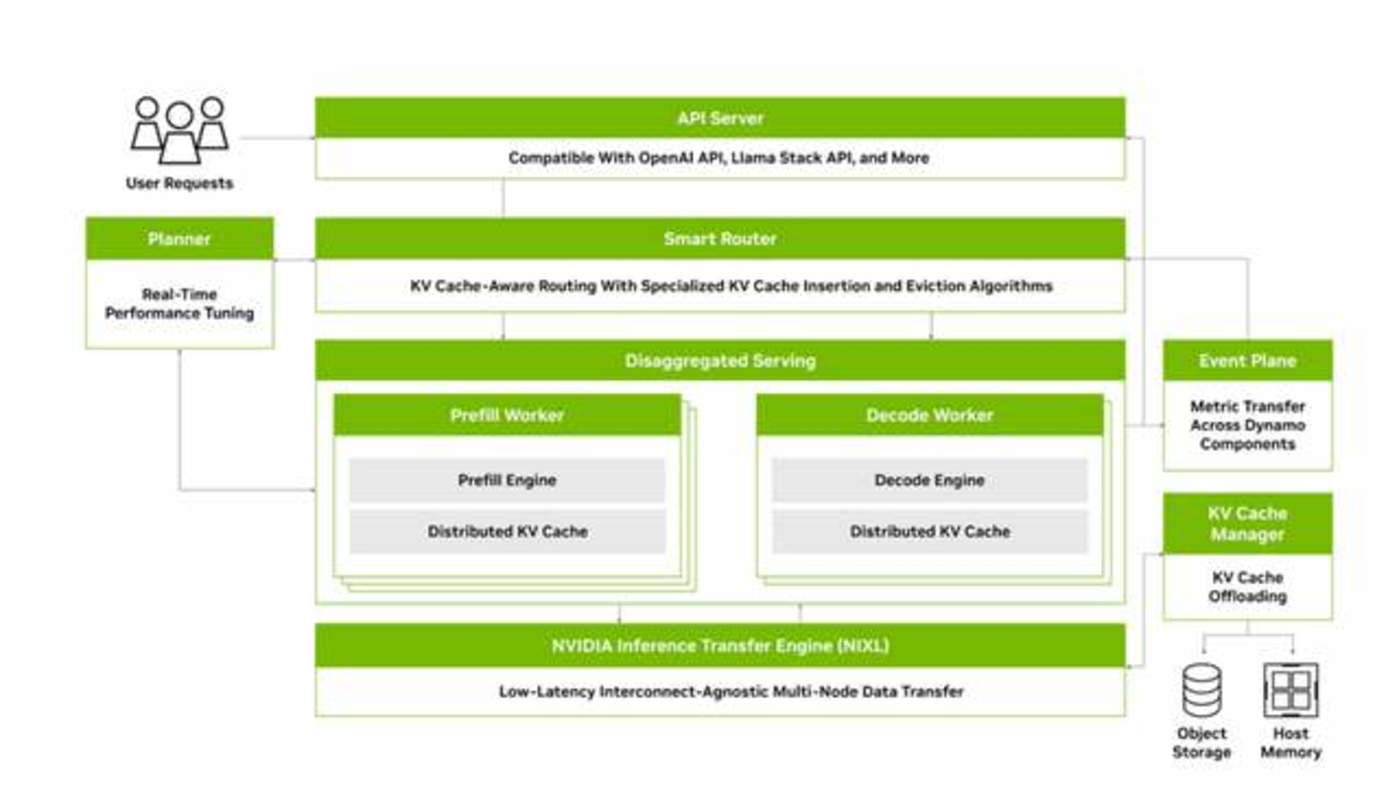
3. 低延迟通信库 (Low-Latency Communication Library):这个推理优化库支持先进的 GPU 到 GPU 通信,并简化异构设备之间的复杂数据交换,从而加速数据传输。
4. 显存管理器 (Memory Manager):这是一种可在不影响用户体验的情况下,以智能的方式在低成本显存和存储设备上,卸载及重新加载推理数据的引擎。这类似于把不常用的工具先放入仓库,需要时再拿出来,留出昂贵的工作台空间 (高性能显存) 给当前最紧要的工作。这种分层存储和快速调取的策略,让 GPU 显存的利用更高效,推理成本能随之下降。

而有了以上的这些优化路径,黄仁勋想在 AI 逐渐转向推理时代之际,让英伟达依然保持 AI 芯片的霸主地位。
根据英伟达的官方数据,在相同数量的 GPU 下,使用 NVIDIA Hopper 架构的 GPU 跑的 Llama 大模型,在采用 Dynamo 后的整体推理性能和产生的结果数量直接翻倍,在由 GB200 NVL72 机架组成的大型集群上运行 DeepSeek-R1 模型时,Dynamo 让每张 GPU 每秒能生成的 token 数量提升了超过 30 倍。

孙田浩
美国二级市场投资人
某新加坡联合家办资深分析师:
英伟达在这条路上走得比其他人越来越远了,所以我觉得它传递的 Key Message(重要信息) 就是 all in 推理。它把所有的精力都花在推理这条线上,然后让其他人追不上它。
在今年的 Keynote 中,老黄的名句也变了:从 「The more you buy, the more you save」(买得越多,省得越多),变成了 「The more you buy, the more you make」(买得越多,赚得越多)。

这意味着英伟达的 AI 数据中心已经准备好服务推理侧的客户,帮助客户省钱提效。也意味着,英伟达想在推理侧继续成为算力霸主。
03 数据中心基建
要配合这样更大规模集群的建设,相关的数据中心基建和上下游也需要随之更新了。
上文我们提到过,芯片架构的取名方式更新,代表着黄仁勋对 「集群」 生态的强调,而非单芯片。而对应的,数据中心中的机架架构也将升级为 「Kyber」,通过计算托盘旋转 90 度,从而实现更高的机架密度。
Kyber 现场展示
这个是我们未来的 Kyber Generation,是下一代产品。这就是一个 72 个 GPU 的 GB200,总共有 288 个 GPU(72*4)。

除了机架的更新之外,整个数据中心的制冷、供电也都需要为新一代的芯片升级。
Mark Luxford
Vertiv 工作人员:
正如黄仁勋在主题演讲中宣布的,我们将推出 Vera Rubin 和 Vera Rubin Ultra(配套基建设施)。我们平时与英伟达的合作非常紧密,我个人每周与他们沟通四次,来共同制定了这代产品的参考设计。
每代产品都这意味着需要更高功率,会需要更强的冷却能力,我们正在响应这一需求,同时确保系统架构和冷却管道能够正常运行,CDU(冷却分配单元) 能够扩展以满足新的需求。就比如我们已经把 CDU 从 1 兆瓦升级到了 2.3 兆瓦,这将非常适合 Vera Rubin Ultra,能毫无压力地处理 600 千瓦功率的机架。

这只是系统的一部分,我们还需要重新设计风冷系统。我们会在机架级别的服务器中提取热量,并通过 CDU 与设施电路进行热量交换。然后通过冷冻机、冷却塔、干式冷却器甚至通过热泵将热量排放到空气或大气中,或者将其用于城市供暖等用途。

硅谷 101 真正密切关注着数据中心的基建、电力系统、上下游供应链等方向,未来会更深度地聊聊。
04 推理时代:群雄逐鹿还是单一霸主?
在 AI 训练侧,英伟达是绝对的霸主地位,但在 AI 进入推理侧之际,AMD、Groq、谷歌 TPU 还有 ASIC 这些玩家有机会分掉英伟达的蛋糕吗?
David Xiao
CASPA 主席
资深芯片从业者
ZFLOW AI 创始人兼 CEO:
在 2023 年的时候,我们请黄教主到华美半导体协会,我当时还挑战性地问了一个问题。因为我自己做 AI 芯片很多年,我就问他:GPU 架构在很多应用场景下的效率其实不高,而我们在做各种定制的 AI 芯片,比如稀疏化的 (Sparsity)、基于 RISC-V 的,或者像 Cerebras 这种基于 wafer-scaling(晶圆微缩) 的大芯片等,那我们是不是还有机会?老黄对于我这个问题的回答是:「大家都有机会,但是你们的机会不大。」
在我们对话的嘉宾中,无论是投资人、还是芯片领域的人,对于 「大家都有机会,但机会不大」 这个结论都基本赞同。
原因是英伟达目前的生态已经太完整,护城河已经太高了,不仅仅是单个 GPU 的性能,而是整个大集群的高效联通,以及 CUDA 软件层面的优化和支持。并且如我们上文所说的,英伟达在领先对手的情况下,还在不停地加固新的护城河。

比如说大家非常关注的 「千年老二」AMD,一直没有能在 AI GPU 这方面取得突破性的市场份额,在过去一年,股价也下滑了超过 40%。归根结底,还是软件方面追赶不上英伟达。
孙田浩
美国二级市场投资人
某新加坡联合家办资深分析师:
AMD 的 MI300 发的时候,对标的是英伟达的 H100、H200。H100 的内存是 80G,但 MI300 直接是 128G;MI350 是 192G,英伟达的 B 卡才 190G。AMD 不仅卡的内存高,而且还比英伟达便宜 40%。虽然它参数看起来都很厉害,但我去测试的时候发现,AMD 的实际的性能远低于它写的参数。
原因有两个:第一,真的去开发、测试 ROCm(AMD 的软件,CUDA 的对标品) 的时候,软件全是 bug(故障),根本就跑不通模型,推不出来。第二,AMD 目前做得比较成熟的就是 8 张卡互联,我都没见到过 64 个卡互联。但英伟达在 2027 年都要 576 个卡互联了,这之间的差距已经没办法去弥补了。
更何况英伟达有 NV Switch,AMD 是没有相应的芯片的,没有做出类似成型的东西。AMD 虽然有替代 NVLink 的东西,但是它稳定的效率是 NVLink 的二分之一。而没有 NV Switch 它又做不了集群,只能 8 个卡互联,所以我觉得在互联的差距更大,更赶不上。

但并不是说 AMD 在一些特定的市场没有机会。二级市场投资人们认为,客户们不可能接受一家独大,一定会给予 AMD 和其它芯片厂商一些机会。但在端模型起来之前,最大的份额可能依然会被英伟达所占据。
而至于 ASIC 这样的专用集成电路,虽然也会有它们特定的市场,但可能也占据不了太多英伟达的份额。
David Xiao
CASPA 主席
资深芯片从业者
ZFLOW AI 创始人兼 CEO:
AMD 在大力推 AI PC,包括也在推它的 GPU。但是它推的方式,可能是去跟一些大模型的厂商直接合作,比如说某一个大模型在它这个场景下用得很好,而且这个应用场景又非常广,那在这种情况下也是有机会的。

孙田浩
美国二级市场投资人
某新加坡联合家办资深分析师:
AMD 的故事是在三到五年以后,当端侧的东西都起来了,C 端的应用大模型的成本已经非常低的时候,比如一个电脑、一个 GPU 也可以去训练大模型、做 AI 的时候。可以这么理解,在 GPU 这个领域,除了英伟达以外,只有 AMD 配在这个市场上活着,所以它就能吃那些中长尾的份额。
陈茜
硅谷 101 视频主理人:
Groq 呢?ASIC 呢?他们不配活着吗?
孙田浩
美国二级市场投资人
某新加坡联合家办资深分析师:
ASIC 落地的难度是非常高的,而且通用性很窄。第一是它量产很难,谷歌的 TPU 核心计算单元的 transistor(晶体管),大小比英伟达要大 2~4 倍,背后的原因是它设计能力的不足,而芯片做大后,会导致良率下降,所以谷歌的 TPU 的良率 90% 都不到,英伟达的可能是 99%,结果就是 TPU 量产很难,很多时候只能满足大厂一两个需求。
第二,ASIC 的核心是根据客户的业务来设计芯片,当然中间很复杂,需要先了解客户的业务、知道客户的是代码怎么写的,再根据这些代码去设计硬件的芯片。谷歌的芯片只能在谷歌的生产里用,亚马逊的芯片只能在亚马逊的生产里用。

所以我觉得未来的推演,ASIC 和 GPU 是共存的。英伟达会拿绝大部分通用的计算需求,然后 ASIC 它可能会拿走一些大厂部分的业务场景。比如谷歌有那么多 TPU,但是它也采购了大量的英伟达的卡,因为它那些英伟达的卡是要用到它自己的云上面给客户用的,它的 TPU 只用在训练或者搜索上,应用场景还是比较局限的。
所以看起来,就像老黄说的,无论在训练侧还是在推理侧,「大家都有机会,但机会不大」。英伟达不可能吃掉整个算力蛋糕,特别是当我们进入推理时代,出现越来越多特定环境的应用需求,越来越多端侧的需求,这时候市场是足够大的,能容忍多个玩家。

任扬
济容投资联合创始人:
如果咱们只从这个算力的一个角度来说,我觉得 Inference(推理) 的竞争会比 Training(训练) 更激烈。如果把这个视角放大一点的话,Nvidia 其实不是在和 AMD、Groq 或者 ASIC 这些去竞争,它其实是在和云计算厂商去竞争,比如 Amazon、Microsoft,而算力是这里面非常重要的一个子战场。
David Xiao
CASPA 主席
资深芯片从业者
ZFLOW AI 创始人兼 CEO:
老黄有个策略是,可以用上一代的旧卡做推理,新一代卡做训练。因为旧卡有折扣了,跟其他 AI 芯片公司在推理场景中竞争时是有优势的。同时对很多人来说,如果训练跟推理的软件框架是一致的,后面软件部署的成本也会降低,这也是英伟达旧卡在推理市场的优势。
英伟达有很多的打法,它可以去定制推理卡。也可以在产能受限的情况下,只用旧卡来做推理,针对训练做这种又大、又能够横向拓展的新卡。老黄手里面的牌还是非常多的,完全可以选择做或者不做 ASIC。
业内人士们依然对英伟达的护城河和市场优势抱有非常大的信心,但同时我们确实也感觉到,英伟达的股价在最近受到不少压力。有美股机构投资人对我们表示,除了宏观大环境的压力之外,GPT-5 这样的大模型性能表现依然是影响市场的重大因素。
刘沁东
济容投资首席投资官:
因为投资人都是一帮简单粗暴的人,我觉得能够给投资人信心的,就是 GPT-5 出来后,让大家看到:堆算力还是有效,而且把模型带到了下一个境界。那英伟达的股价可能就又都冲回来了。如果没有的话,我觉得要花相当长一段时间,让世界理解了英伟达在生态链中的重要性,英伟达的股价才会慢慢到它该有的位置。

05 全生态超级碗模式
我们此前的数期节目都提到,黄仁勋是一个眼光非常长远的 CEO。而他这次传递出的一个重要信号,就是 「全生态布局」:今后任何一个需要加速计算的领域,他都不会错过。

让我们记忆很深刻就是:在这一次的演讲当中,黄仁勋背后出现这一排像塔罗牌一样的全生态布局,标题是 「为每一个产业服务的 CUDA-X」。包括数值计算、计算光刻、5G/6G 信号处理、决策优化、基因测序、医学成像、天气分析、量子计算、量子化学、深度学习、计算机辅助工程、数据科学和处理、物理学等等。
其中,量子计算、自动驾驶和机器人赛道中的仿真平台和算法,也是英伟达目前着重布局的方向。总的结论是:黄仁勋不会放过任何一个需要算力的市场。

而黄仁勋也发出了很强劲的信号,他说 2024 年 GTC 大会就像一个 Rock Concert,一个秀肌肉、炫酷的摇滚音乐会。而 2025 年的 GTC 大会是美国橄榄球 Super Bowl(超级碗)。因为 Super Bowl 号称 「美国春晚」,里面的所有人,包括两个参赛的队伍、广告商、转播商、观赛游客,每个人都是赢家。
黄仁勋讲的 「全生态超级碗模式」 的故事是 「Nvidia is gonna make everyone a winner.」 也就是说,在英伟达生态中每个人都是赢家。

黄仁勋
英伟达创始人兼 CEO:
我们制定了一套年度路线规划图供大家参考,以便大家更好地规划建设 AI 基础设施。同时,我们正在构建三大 AI 基础设施:云端 AI 基础设施、企业级 AI 基础设施以及机器人 AI 基础设施。

黄仁勋预测 2028 年数据中心支出将会突破 1 万亿美元,而到那时,AI 生态会如何发展?英伟达的霸主地位,是否如我们节目中嘉宾们预测的那样将持续保持?而剩下的蛋糕中又会有什么新机会?硅谷 101 会持续为大家关注未来的动向。
