(图片来源:钛媒体 AGI 编辑林志佳拍摄)
随着 DeepSeek 引发 AI 算力优化热潮,蚂蚁集团全面发力 AI 技术,基于中国 AI 芯片进行 Infra,实现了模型技术突破。
3 月 24 日消息,钛媒体 AGI 获悉,近日,蚂蚁集团 CTO、平台技术事业群总裁何征宇带领 Ling Team 团队,利用 AI Infra 技术,开发了两个百灵系列开源 MoE 模型 Ling-Lite 和 Ling-Plus,前者参数规模 168 亿,Plus 基座模型参数规模高达 2900 亿,相比之下,AI 行业估计 GPT-4.5 参数量 1.8 万亿,DeepSeek-R1 参数规模达 6710 亿。
同时,论文显示,蚂蚁团队在模型预训练阶段使用较低规格的硬件系统,将计算成本降低约 20%,达 508 万元人民币,最终实现与阿里通义 Qwen2.5-72B-Instruct 和 DeepSeek-V2.5-1210-Chat 相当的性能。
目前,相关技术成果论文发表在预印版 Arxiv 平台上。据彭博,该模型在训练阶段使用的是国产 AI/GPGPU 芯片产品,并非完全使用英伟达芯片,但最终得到的结果与英伟达芯片 (如 H800) 的结果相似。
这是蚂蚁集团首次详细披露其在 AI 算力层面的进展,第一次揭秘了自身如何以远低于 DeepSeek、OpenAI 等强大模型所需的计算成本,完成 AI 大模型技术的训练并将其开源,从而加入了中美 AI 科技竞争热潮中。

近年来,大语言模型发展迅速,尤其是 DeepSeek 热潮,引发学界和业界对通用人工智能 (AGI) 的广泛讨论,而混合专家 (MoE) 模型在特定任务中表现优异,但训练依赖高性能计算资源,成本高昂,限制了其在资源受限环境中的应用。
蚂蚁 Ling 团队认为,虽然 MoE 模型训练对高性能 AI 芯片 (如 H100 和 H800) 需求大,且资源供应,但低性能加速器更易获取且单位成本效益高,因此,模型需要能在异构计算单元和分布式集群间切换的技术框架。同时在 AI Infra 部分,在跨集群、跨设备的兼容和可靠层面进行性能优化。该公司设定的目标是“ 不使用高级 GPU” 来扩展模型。
具体来说,蚂蚁 Ling 团队在模型训练环境、优化策略、基础设施、训练过程、评估结果、推理等层面都进行优化和落地。
其中在预训练层面,蚂蚁构建约 9 万亿 token 的高质量语料库,采用创新的 MoE 架构,分析缩放规律确定超参数,多阶段训练并应对瞬时尖峰问题,并且通过优化模型架构和训练策略,如选择匹配架构、集成训练框架、开发 XPUTimer 和 EDiT 策略等,提高训练效率。
论文显示,在 AI 异构计算平台上,技术人员们将多个训练框架集成到统一的分布式深度学习框架中,即开源项目 DLRover。同时,为了利用各种平台的具体特性,团队开发了轻量级调试工具 XPUTimer,有助于快速、高效进行任务性能分析,并将内存使用量减少 90%。而 EDiT(弹性分布式训练) 则在各种配置下,训练时间最多可减少 66.1%。
此外,在存储优化中,通过存储与训练流程的协同设计,提升 MoE 场景下的 I/O 效率,通过 5000 个加速器 MoE 训练任务,将检查点写入延迟降低了 50%,减少一半的时间消耗,同时还将训练节点上的峰值内存消耗降低了 60%。
蚂蚁技术团队表示,利用 Ling-Plus,在五种不同的硬件配置上对 9 万亿个 token 进行预训练,其中,使用高性能硬件配置 (配置 D) 训练 1 万亿 token 的预训练成本约为 635 万元人民币,但蚂蚁的优化方法将使用低规格硬件将成本降至 508 万元左右,节省了近 20% 的成本。
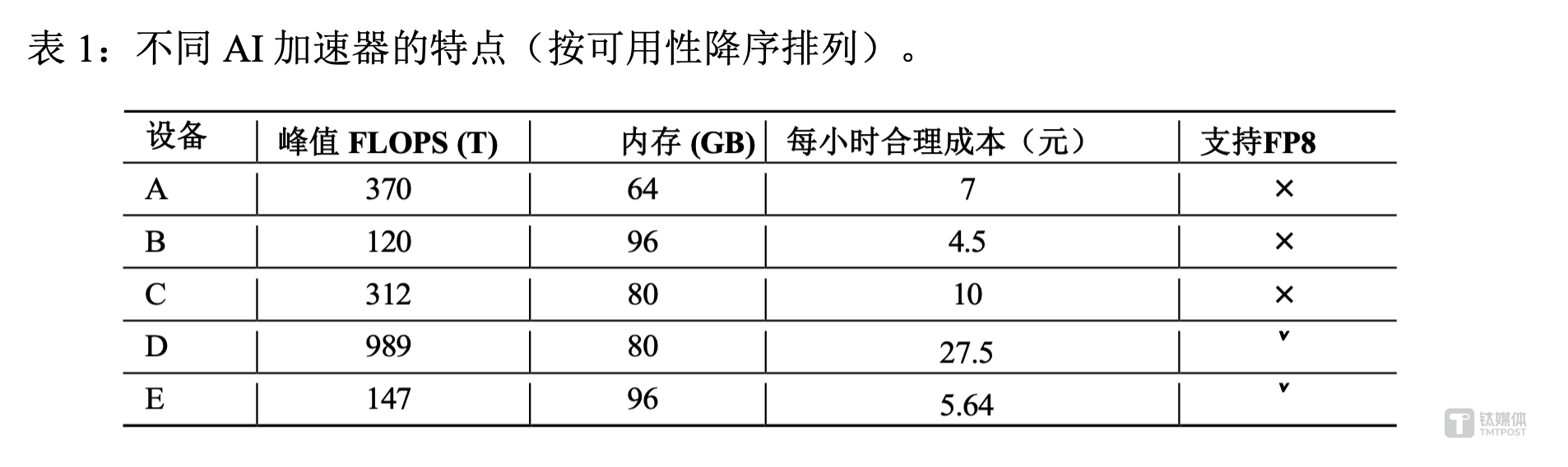
蚂蚁表示,这一结果证明了在性能较弱的硬件上训练最先进 (SOTA) 的大规模 MoE 模型的可行性,使得在计算资源选择方面为基础模型开发提供更灵活、更经济的方法。
根据蚂蚁论文提供的 FLOPS 峰值,钛媒体 AGI 认为,这些 AI 加速器产品中可能包括壁仞、天数、寒武纪的算力芯片技术。
这与英伟达的初衷背道而驰。英伟达 CEO 黄仁勋认为,即使 DeepSeek 的 R1 等更高效的模型出现,计算需求仍将增长,AI 大模型需要更好的芯片来创造更多收入,而不是更便宜的芯片来削减成本。他坚持打造具有更多处理核心、晶体管和更大内存容量的高性能 GPU 芯片和“AI 工厂”。
结果显示,在英语理解方面,蚂蚁论文中表示,Ling-Lite 模型在一项关键基准测试中的表现优于 Meta 的 Llama 3.1-8B 模型。在中文基准测试中,Ling-Lite 和 Ling-Plus 模型均优于 DeepSeek 的同类模型。
“Ling-Plus 和 Qwen2.5-72B-Instruct 在安全性方面表现突出,且 Ling-Plus 在错误拒绝方面表现更佳。DeepSeek 系列模型的错误拒绝现象最少,但部分安全性较低。而 Ling-Plus 在安全性和拒绝率之间表现出更好的整体平衡,在这些指标的平均值方面取得了最好的结果。” 论文表示。
据悉,蚂蚁百灵大模型 Ling-Plus 和 Ling-Lite 将计划开源,并应用于医疗、金融等行业领域。
目前,蚂蚁拥有三款 AI 助手管家产品—— 生活助手“ 支小宝”、AI 金融管家“ 蚂小财”,以及刚刚发布的 AI 医生助手等产品和解决方案。
不过,蚂蚁也在论文中表示,大模型训练是一个具有挑战性且资源密集的过程,经常伴随着各种技术困难,错误和异常很常见,有些相对容易解决,而有些则需要大量时间和精力。而 Ling 系列模型在训练阶段面临挑战,包括稳定性,即使是硬件或模型结构的微小变化也会导致问题,包括模型错误率的大幅上升。
针对这份论文,彭博行业研究高级 BI 分析师 Robert Lea 表示,蚂蚁的这一成果强调了中国 AI 创新能力不断增强,以及技术进步的步伐加快。如果内容得到证实,这将凸显出中国正在朝着 AI 自给自足的方向迈进,因为中国正在转向成本更低、计算效率更高的模型,以绕过英伟达芯片的出口管制。

(本文首发于钛媒体 App,作者|林志佳)

更多精彩内容,关注钛媒体微信号 (ID:taimeiti),或者下载钛媒体 App
#蚂蚁自研 2900 亿大模型用国产 AI 芯片训练计算成本 508 万元低于 DeepSeek 钛媒体 AGI
