文 | 智见 Time,作者 | 经纬,编辑 | 308
国家网信办公布数据,截至 2024 年 3 月,国内共有 117 个 GenAI 完成了备案。坊间常说的 「百模大战」 也从戏谑与夸张变成了纸面上的真实。
国内外各大厂商纷纷发力,你方唱罢我登场,各种应用也纷纷落地,似乎要在今天就实现 AI 技术的未来。不可否认的是,AI 淘金热已经开始了:不仅有 「黄金」 而且很 「热」。
(图源:英伟达股价)
但一个问题接踵而至,相比各大厂商贴钱大搞大模型,股价高歌猛进的确实如英伟达等一众硬件厂商。19 世纪淘金热时期的那个道理被再一次证明了:卖铲子,有时比挖金子更赚钱。
然而放在今天这个AI时代,大模型与芯片,不仅仅是 「金矿」 与 「铲子」 的关系。
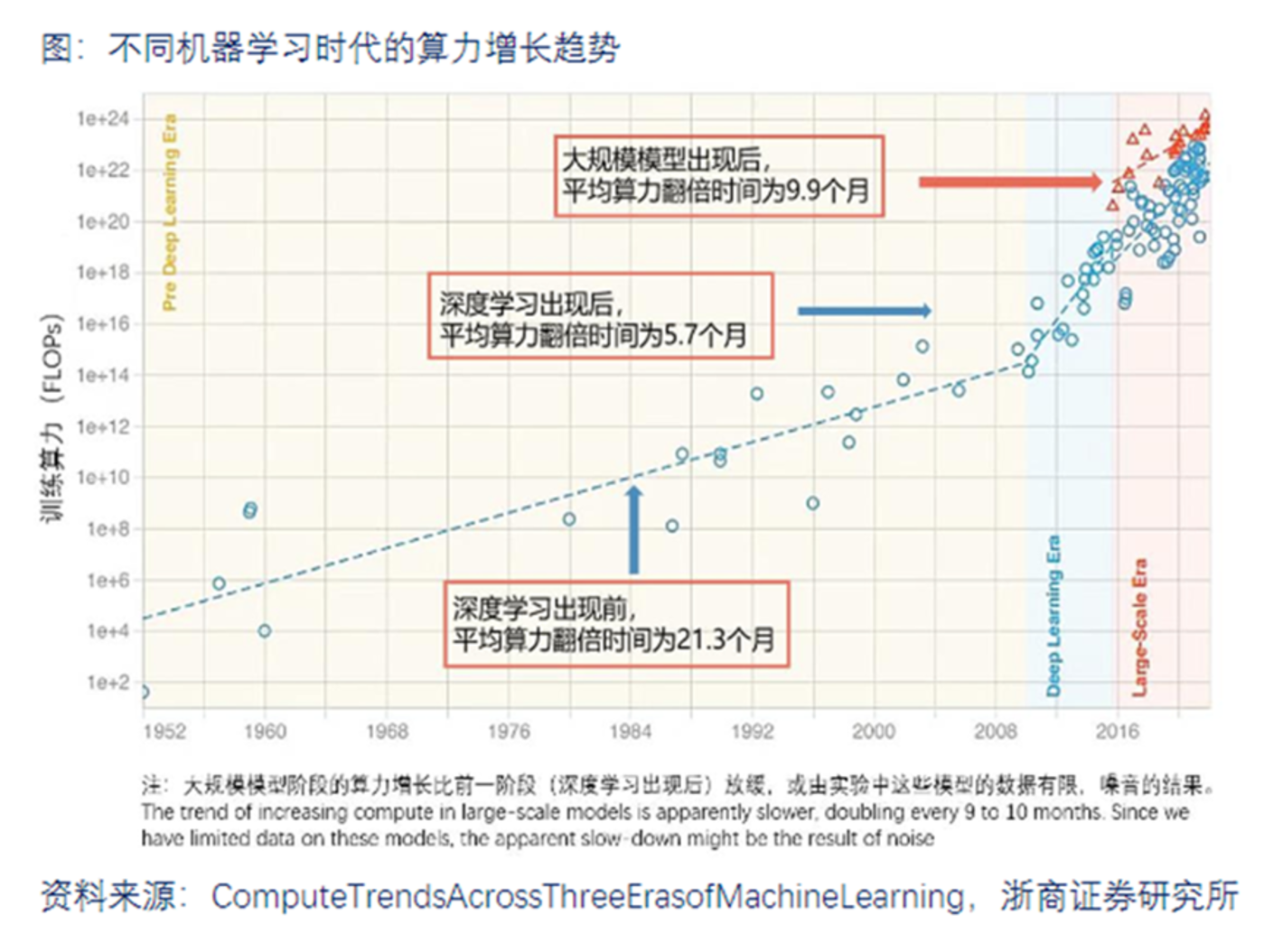
(图源:浙江证券研究所)
生成式 AI 的算力消耗巨大,而且算力的需求在可预见的未来只会进一步加大。中国信通院曾测算,2025 年全球算力规模将达 6.8 ZFLOPS(每秒十万京次 (=10^21) 的浮点运算),与 2020 年相比提升 30 倍;到 2030 年,这个数据有望增至 56ZFLOPS。此外,芯片的其他性能,如储存空间、带宽等也将直接影响大模型的响应交互速度。
某种意义上来说,硬件决定了大模型的上限。
然而残酷的是,硬件性能的提升,在逐步接近一个 「上限」:晶体管微缩越来越难,用 「老办法」 提升算力并降低功耗变得越发难以实现。
此外,现有基于冯·诺依曼的 AI 芯片架构面临 「储存墙」 等诸多问题,恐难以满足日后 AI 发展的需求。而 GPGPU 受制于高功耗与低算力利用率,ASIC 芯片的弱通用性难以满足未来行业内更多的定制化需求。
同时,在各大模型鲸吞算力的今天,拥有上万,甚至数十万张芯片的算力体系将逐渐成为 AI 基础设施的 「入门级」 配置。如何保障庞大数量的 AI 芯片协同运作,如何降低系统内耗,做到 「1+1 不小于 2」,也是行业面临的问题。
于是,即使强如ChatGPT,也很难面对 「无米之炊」。
所以,越来越多的行业人士意识到,靠 「暴力」 堆叠算力的时代已即将过去,如何 「智取」 才是下一步行业发展的新方向。
打破芯片中的」 第四面墙"
无论是打败了全球为其高手的 AlphaGo,还是已经爆火的 ChatGPT,其功能的实现离不开 AI 芯片。但无论何种芯片,只要基于传统冯·诺依曼架构,都会面临 「存储墙」 的问题。
在传统的冯诺依曼架构中,计算和存储功能分别由中央处理器和存储器完成。CPU 与存储器相互独立,数据传输需要通过总线来进行。在数据较多的情况下,计算速度往往会被总线的性能 「卡脖子」。
在现今的 AI 时代,进行大模型训练的 GPU 需要处理大量数据,同时要求更强的并行处理能力。所以当总线数据传输速度不够时,整个系统的运转效率就会被严重拖累。
亿铸科技 CEO 熊大鹏在 「2024 算力技术创新发展生态大会」 上公开表示:「过去 20 年峰值算力提高了 90000 倍,但内存带宽仅提高了 100 倍,互联带宽仅提高了 30 倍。」
无独有偶,不仅芯片内部数据传输速度受到限制,芯片与芯片间的传输也遇到了瓶颈。同时,服务器内部之间或与其他设备的数据传输、控制和管理等接口功能的要求也随之增加。
「可以说带宽的发展速度严重滞后于算力的发展速度」,熊大鹏说。
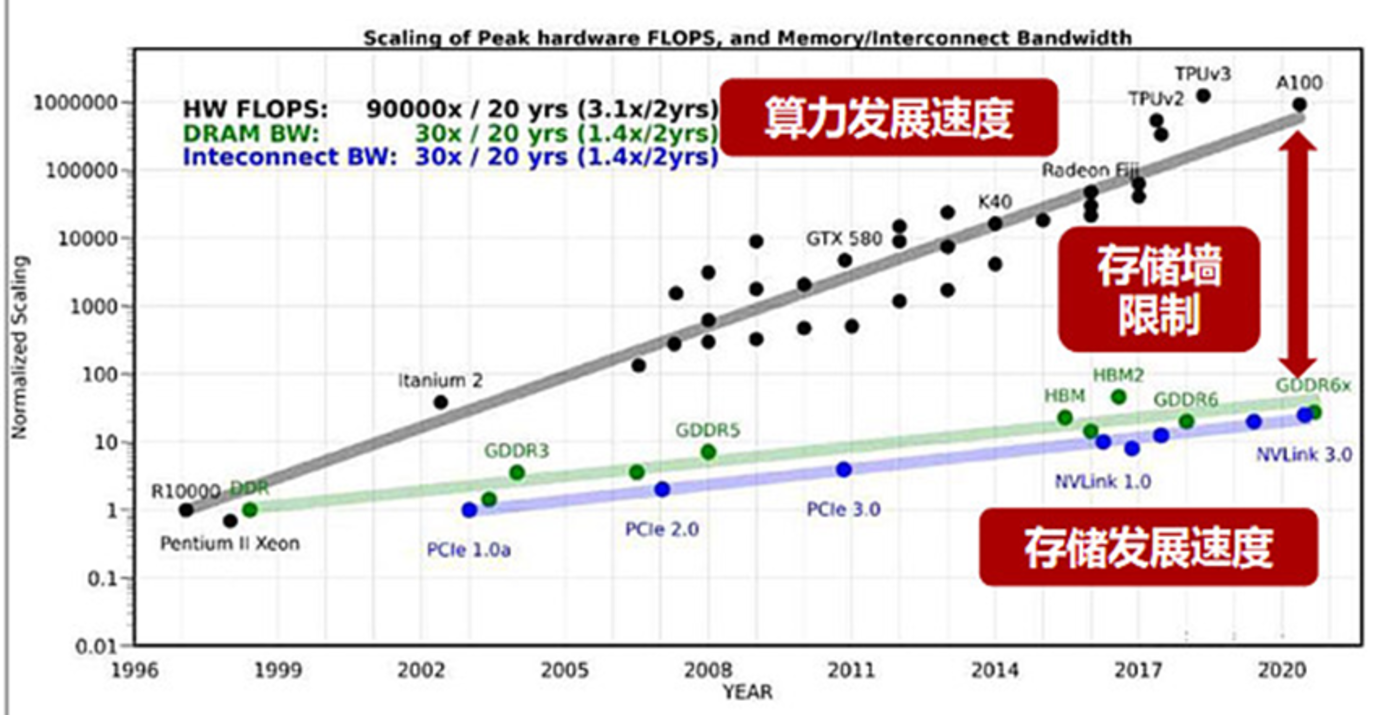
(存储器的体现,图源:浙江证券研究所)
冯诺依曼架构带来的 「木桶效应」,最直接的表现就是严重的能耗浪费。由于存储与计算在不同的位置,数据的频繁搬运成为了必然。同时,大量的数据搬运使得编译器难以在静态可预测的情况下对算子、函数、程序或者网络做整体的优化,只能手动、一个个或者一层层对程序进行优化,耗费了大量时间与能源。
根据英特尔公布的数据,当半导体工艺达到 7nm 时,数据搬运功耗高达 35pJ/bit,占总功耗的 63.7%。另有统计表明,在大算力的 AI 应用中,数据搬运操作消耗 90% 的时间和功耗,数据搬运的功耗是运算的 650 倍。
对此问题,目前业界比较典型的方案是 「缩短距离」 和 「拓宽道路」:使用 3D 封装、高带宽内存等技术来缩短存储器和处理器之前的距离,并提高数据带宽。
但近存计算技术本质上仍然是存算分离的冯·诺依曼架构,可以在一定程度上减少数据搬运及其开销,但不能从根本上消除冯•诺依曼架构带来的问题。
于是,「存算一体」 的芯片架构成为了更优的选择。在 「存算一体」 架构中,所有的计算都可以在存储器内实现,基本上消除了 「数据搬运」 的问题,用 「剩下的木板」 拼成了 「更高的水桶」。
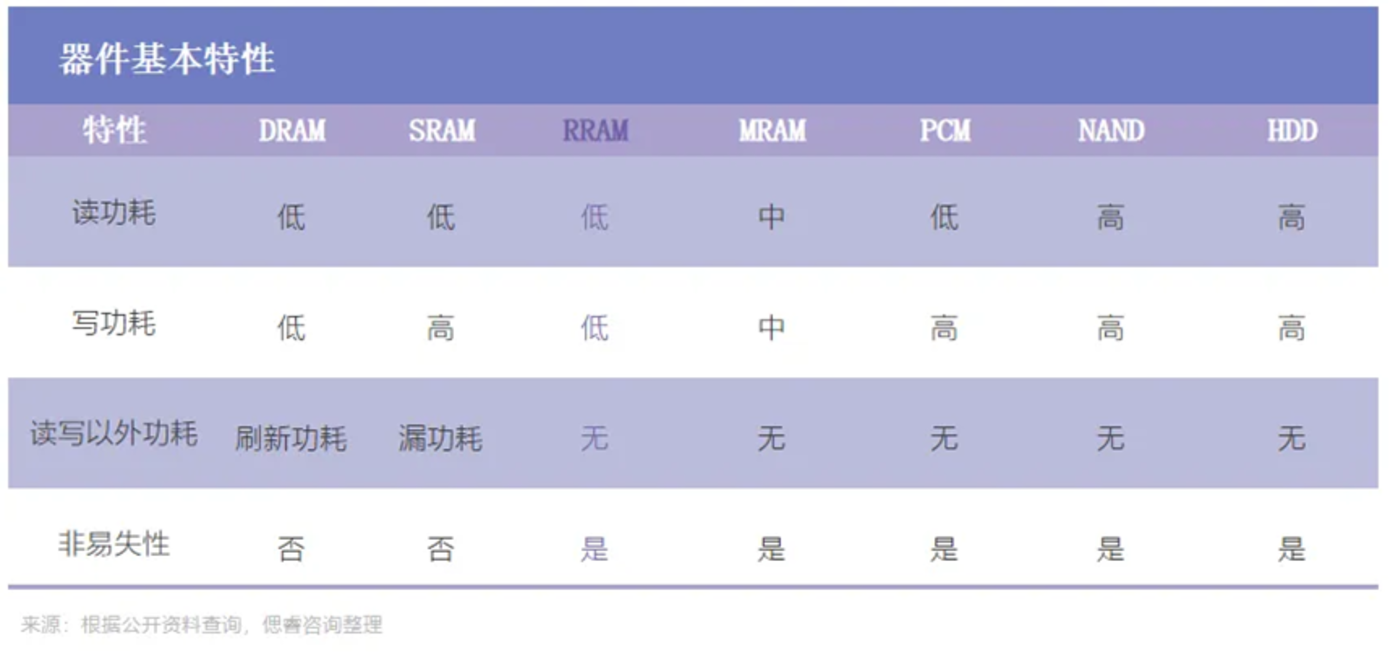
所以,「存算一体」 成为了行业不约而同追捧的主要技术路线之一。但达成存算一体,各家的技术路线各有不同。总的来说,基于传统存储介质的存内计算芯片,如静态随机存储器 (SRAM) 和 NOR 闪存 (Hash),已相对成熟,如九天睿芯、后摩智能、苹芯科技等厂商已推出或量产 SRAM 芯片,知存科技 NOR 闪存芯片也已量产。而基于新型非易失性存储器介质的存内计算芯片,如磁性随机存储器 (MRAM)、阻变随机存储器 (RRAM)、相变存储器 (PCM)、铁电存储器 (FeFET) 等则多处于摸索阶段。
忆阻器 (RRAM) 也是实现 「存算一体」 的重要技术路线之一。
具体来说,如果用交叉阵列的方式做忆阻器,就可获得类似矩阵的结构。这种结构可以根据需求完成存储和计算的功能。需要存储时,数据可以存储在忆阻器内;需要计算时,忆阻器可以直接进行计算。同时忆阻器还有如尺寸小、速度快、与 CMOS(互补式金氧半导体) 工艺可兼容等其他优点。
 亿铸科技的 「存算一体」 架构正是基于忆阻器实现。亿铸科技自 2020 成立以来,就专注于研发基于 RRAM 的全数字存算一体大算力 AI 芯片,目前已经完成了数字存算一体原型技术验证 (POC) 芯片的回片及成功验证。该芯片的能效比表现惊人,在测试中能够达到同等工艺下传统架构 AI 算力芯片的 20 倍以上。
亿铸科技的 「存算一体」 架构正是基于忆阻器实现。亿铸科技自 2020 成立以来,就专注于研发基于 RRAM 的全数字存算一体大算力 AI 芯片,目前已经完成了数字存算一体原型技术验证 (POC) 芯片的回片及成功验证。该芯片的能效比表现惊人,在测试中能够达到同等工艺下传统架构 AI 算力芯片的 20 倍以上。
亿铸科技 CEO 熊大鹏认为,「存算一体」 将打破摩尔定律,开启算力第二增长曲线。
万卡集群,万箭齐发
单个芯片算力的提升是目前芯片行业追求的目标。但同时,有道是 「一个好汉三个帮」,由大量芯片组成的算力集群以及其相关的建设也越来越受到行业重视。
自从大模型问世以来,行业对算力的需求就不断提升。ChatGPT 的爆火,离不开背后庞大算力的 「力大飞砖」。并且在 「百模大战」 的当下,大模型迭代速度也在加快,对算力的要求也更高。
比如,红极一时的 GPT-4 大模型拥有 1.8 万亿个参数,用 100 天完成训练的话需要使用约 25000 张英伟达 A100 GPU,或 1000 张 H100 GPU,所需算力之大已让行业惊叹。但它的竞争对手们却没有停这场 「军备竞赛」 的脚步:Meta 在 2022 年就宣布建成拥有 16,000 块英伟达 A100 GPU 的 Al 研究超级集群 Al Research Super Cluster。2024 年初,Meta 又公布建成两个新的 AI 数据中心,每个数据中心各拥有超 24000 块英伟达 H100 GPU。马斯克于今年 7 月 1 日透露,Grok 3 的训练使用了 10 万张英伟达 H100 GPU。
然而对于 「N 卡难求」 的我国 AI 行业,有业内专家指出,大模型对算力需求增长已远高于单颗 AI 芯片性能的增长速度,通过集群互联弥补单卡性能不足,也许是当下最值得探索并解决 AI 算力荒的必要路径。
当然,国内企业也掀起了一波数据中心的建设浪潮:
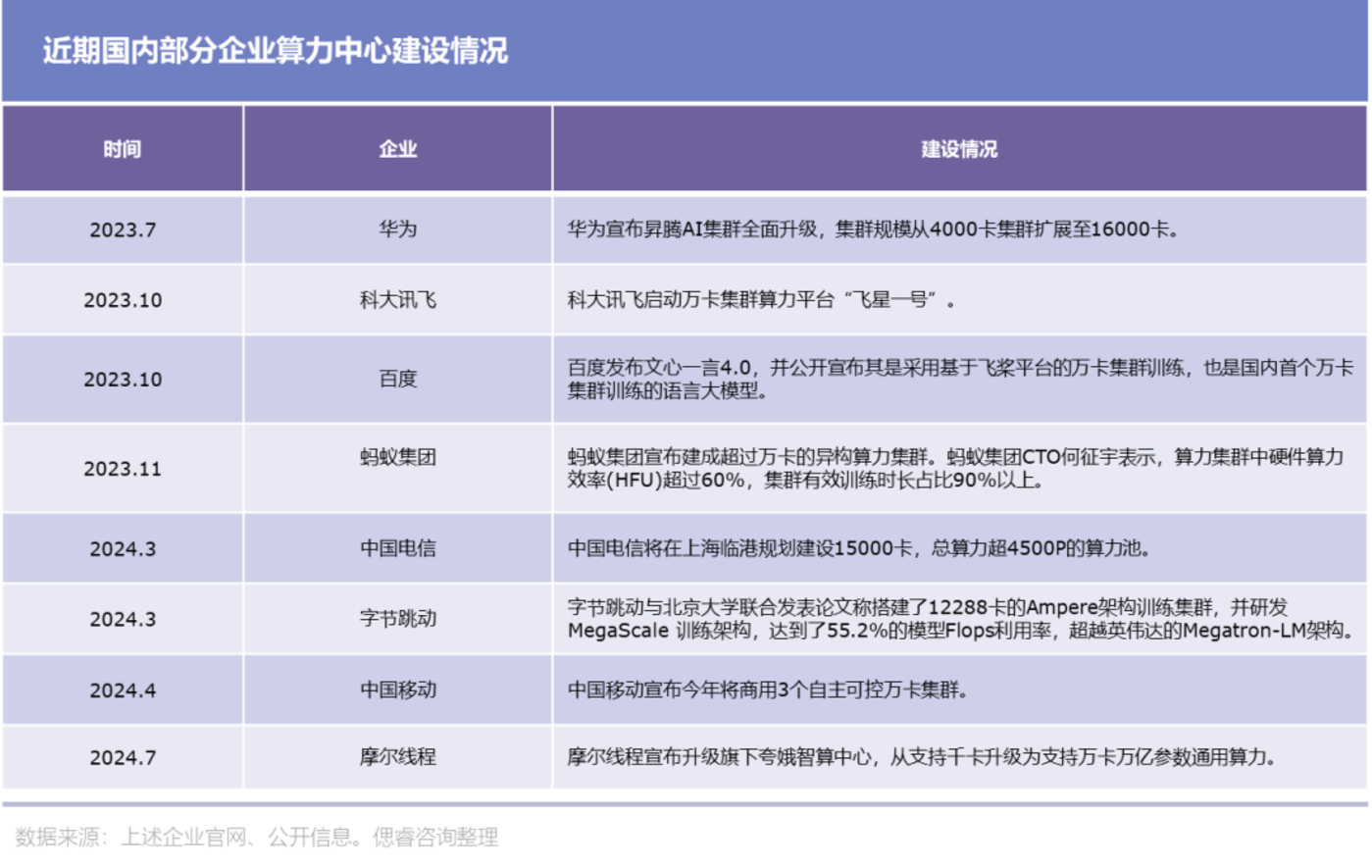
然而建设算力集群并非简单的堆叠,上万张卡以何种方式互相连接,每张卡之间如何通讯,整个集群如何分配任务,如何保证系统的稳定性等诸多问题都需要解决;对除 GPU 以外的硬件,如:交换机、网卡、光模块等提出了更高的要求。
「可以把万卡想象成一个万人团队,需要有非常强的沟通机制,才能协同的把一件事情完成。」 摩尔线程 CTO 张钰勃在 2024 WAIC 上说,「对于万卡集群,仅靠单卡算力还不够,提供匹配单卡算力的通讯也至关重要。」
同时,在故障率不变的情况下,随着算力集群中芯片数量的上升,出现故障的总量也在上升。甚至如果前期建设上出现问题,如芯片之间未能科学有效的连接,故障率可能会进一步提升。如何迅速定位故障、排除故障也是算力集群运维的一个挑战。
除了设备本身的性能和信息交互问题,万卡集群还面临着能耗高、散热难等问题。这不仅不经济、不环保,同时也可能降低设备运行的实际性能和使用寿命。现有的 GPU 发热问题,部分归因于芯片冯·诺依曼架构的 「存储墙」 问题:数据在 「存」 和 「算」 之间大量搬运导致无谓的能量浪费,产生大量废热。这也进一步体现了行业对 「存算一体」 等新技术需求的紧迫性。
然而必经之路上的挑战,是无论如何也需要克服的。未来的搏击场,「万卡」 集群只能换来一个参赛名额。
寻找下一个英伟达
淘金者的最基本目的是淘到金子赚到钱,卖铲子的人目的也一样。
目前来看,人工智能确实正在如某些大佬宣称的那样,在 「重做每个行业」。AI 技术正在与传统行业相融合,产生了如智算中心、AI PC、AI 手机、智能驾驶等产品。
大模型的落地显而易见,AI 已经渗透到了各行各业中。
但而 「卖铲子的人」 呢?
随着大模型对算力与效率的要求逐渐提高,把一个大模型分散在不同算力集群中训练将变得越发困难。各算力集群之间的同步问题、部分敏感数据不能轻易移动、调试以及排除故障的不便等诸多问题使得大模型厂商更倾向于在单一算力集群中训练大模型。
而大模型性能的重要限制因素:硬件性能与算力规模参差不齐,这必将导致有着更多人力、财力、技术力的智算中心将承接更多业务。
这也注定了智算中心这个 「卖铲子」 的,是一个强马太效应的生态位。强者恒强,在经历了行业的大洗牌后,可能仅有了了数家存活。
而目前动辄数亿甚至数十亿的智算中心纷纷 「拔地而起」:
去年 9 月 14 日,武汉人工智能计算中心项目扩容三期项目启动,算力由 200P 扩容至 400P,据公开资料可查,北京神州新桥科技有限公司中标,中标价为 33998.0044 万元,每 100P 折合人民币约 1.7 亿元。
去年 6 月 26 日,摩尔线程官网发布消息称建设贵安摩尔智算中心,一期预计建设不少于 370P 算力的智算中心,计划投资 5 亿,每 100P 算力折合人民币约 1.35 亿元。
去年 2 月 27 日,吉利星睿智算中心正式揭牌,总投资人民币 10 亿元,吉利集团宣称智算中心算力已达 810P,每 100P 折合人民币约 1.23 亿元。
但即使在各地大力建设只算中心的当下,马太效应也似乎并未出现。
因为算力缺口依然庞大。根据美国银行研究数据指出,AI 模型训练所需的算力每 2 年涨 275 倍。大模型训练的 Scaling Law 依然有效。「 源数据」-「Transformer」-「Diffusion」-「涌现」,这条技术路线在短时间内依然是业内铁律。工信部数据显示,2023 年中国数字经济核心产业增加值估计超过 12 万亿元,占 GDP 的比重为 10% 左右,算力总规模达 230EFLOPS,智能算力规模达 70EFLOPS,增速超 70%。
除此之外,AI 技术的跨领域发展,也带来了其他领域的算力需求。如 AI 技术牵动了如 3D、HPC 等技术的发展与融合。在实际应用上,市场对于能够支持 AI+3D、AI+科学计算、AI+物理仿真等多元算力需求日益迫切。
人类在进入一个 AI 的时代,而在芯片的万亿市场中,永远不可能只有英伟达一个玩家。如何选择属于自己的方向和路径,是当下所有人工智能芯片公司需要共同面临的问题。
