「至少有一亿元的 AI 推理一体机硬件需求没有被满足。」「DeepSeek 出来之后,云服务厂商的电话已经被打爆了,全都是咨询 DeepSeek 一体机的。」
这是 「甲子光年」 最近听到最多的两句话。
DeepSeek 在 2025 年春节期间火出圈后,掀起了中国企业本地化部署的风潮,也带火了一款新的产品——DeepSeek 一体机。
怎样形容 DeepSeek 一体机的火爆程度呢?
这么说吧,去年我们在很多科技产业大会上看到最多的产品是机器人。而今年初在一些科技产业大会的外部展览区,机器人的展位有所减少,放眼望去,大片映入眼帘的,是各家厂商推出的 DeepSeek 一体机。
一体机产品,图片来源:「甲子光年」 拍摄
也有服务器厂商的工作人员告诉我们,从春节期间 DeepSeek 火出圈到现在,每天都有铺天盖地的电话打进来,都是来咨询一体机或者本地部署 DeepSeek 大模型的,有时候销售和售前要一天拜访三波客户去做交流和讲解。
交易市场的火热还只是其次。在风起云涌的二级市场,甚至出现了 「一体机概念股」,首都在线、天玑科技、恒为科技、紫光股份、云从科技、广电运通等公司的股票都在近期迎来了不同程度的上涨。
为什么在短时间内出现了 DeepSeek 一体机的大爆发?服务器、云厂商、芯片、软件、集成商……各个领域的科技企业都推出了一体机,它们之间的差别是什么,客户应该怎么选购合适自己的产品?搭载了国产 AI 芯片的一体机跑满血版 DeepSeek 模型的效果又究竟怎样?
一、DeepSeek 带火一体机产品
所谓 「一体机」,指的是一种专门为人工智能大模型应用和部署而设计的集成计算设备,通常包含中央处理器 (CPU)、图形处理器 (GPU)、存储器、操作系统、AI 平台软件及各类模型算法等软硬组件,可以看成是 「大模型+服务器」 的 「1+1」 产品。
换句话说,它是一个 「AI 工具箱」,里面塞满了硬件、软件和行业专用工具,具有数据本地处理、部署周期短、成本低等优点,非常适合政府、银行、医院等对隐私要求高的行业和单位。
其实,一体机并不是新的概念,早在 DeepSeek 爆火之前,就有大模型一体机产品被部分政府和企业应用在了私有化部署等场景中。相较于大型的服务器集群,一体机成本更低、操作更便捷,也更适合中小企业或个人等小规模的业务需求。
既然一体机并不是一个新东西,那为什么 DeepSeek 发布后,一体机这一产品才迅速蹿红呢?这与 DeepSeek-R1 模型本身的技术优势、政府号召、开源策略和资本市场的推波助澜密切相关:
DeepSeek-R1 发布后,由于它的 MoE 架构、MLA 算法大幅降低了模型对算力的需求,加之不同版本蒸馏小模型的推出,让模型部署变得更加容易,无需花重金购置服务器集群就能将模型部署到本地,极大提升了全民部署 DeepSeek 的热情;
自上而下的号召也很关键。春节后党政机关引入 DeepSeek 的需求井喷,北京、广州等多地政务系统宣布全面启用 DeepSeek 大模型,首批 「AI 公务员」 正式上岗,覆盖文件处理、政策咨询等场景;
而在 2 月 19 日国资委召开 「AI+」 专项行动深化部署会后,大模型的本地部署成为刚需,一体机的本地化部署方案恰恰有效解决了金融、政务等敏感领域的数据合规问题,于是多家央国企纷纷加入一体机采购的浪潮;
与此同时,DeepSeek 的模型是开源的,企业可基于其开发定制化的解决方案,结合国产芯片构建软硬一体的生态,DeepSeek 一体机让想做数字化转型、但技术能力欠缺的企业无需支付高昂的模型授权费、通过简单的部署就能用上大模型;加之二级市场 DeepSeek 概念股大涨,众多企业为了自己的股价和估值,也纷纷采购一体机部署 DeepSeek……上述种种因素,都推动了 DeepSeek 一体机的爆发。
「我们预计,两年内、在百人以上的组织里,大模型的渗透率会达到 40%-50%,而一体机会是他们最优先的选择。」 公众号 「算力百科」 主理人、深圳未来智算科技有限公司创始人陈娇娇对 「甲子光年」 表示。
究竟有多少公司在做一体机呢?目前除了互联网公司和做硬件的厂商,那些原来做集成商的、做软件的、做组装厂的、做交换机的企业也都推出了一体机。「只要是 IT 行业相关的公司都在做,即使不是自己研发的,也会 OEM 一个。」 陈娇娇表示。
从分类上看,目前,市面上的 DeepSeek 一体机分为推理一体机和训推一体机两大类。
推理一体机主要面向需要高效推理计算的企业,内置 DeepSeek-R1 满血版 671B、70B、32B 等不同尺寸的模型,价格从几十万到数百万不等,适用于对数据安全性要求较高的企业;
训推一体机则适用于需要进行模型训练和推理的场景,其价格更高、主要用于预训练和微调大模型,能够支持更复杂的训练、推理任务。根据硬件配置和软件调优程度的不同,价格在几十万到几百万不等。
「甲子光年」 根据公开资料,对部分推出 DeepSeek 一体机的厂商做了统计,情况如下所示:
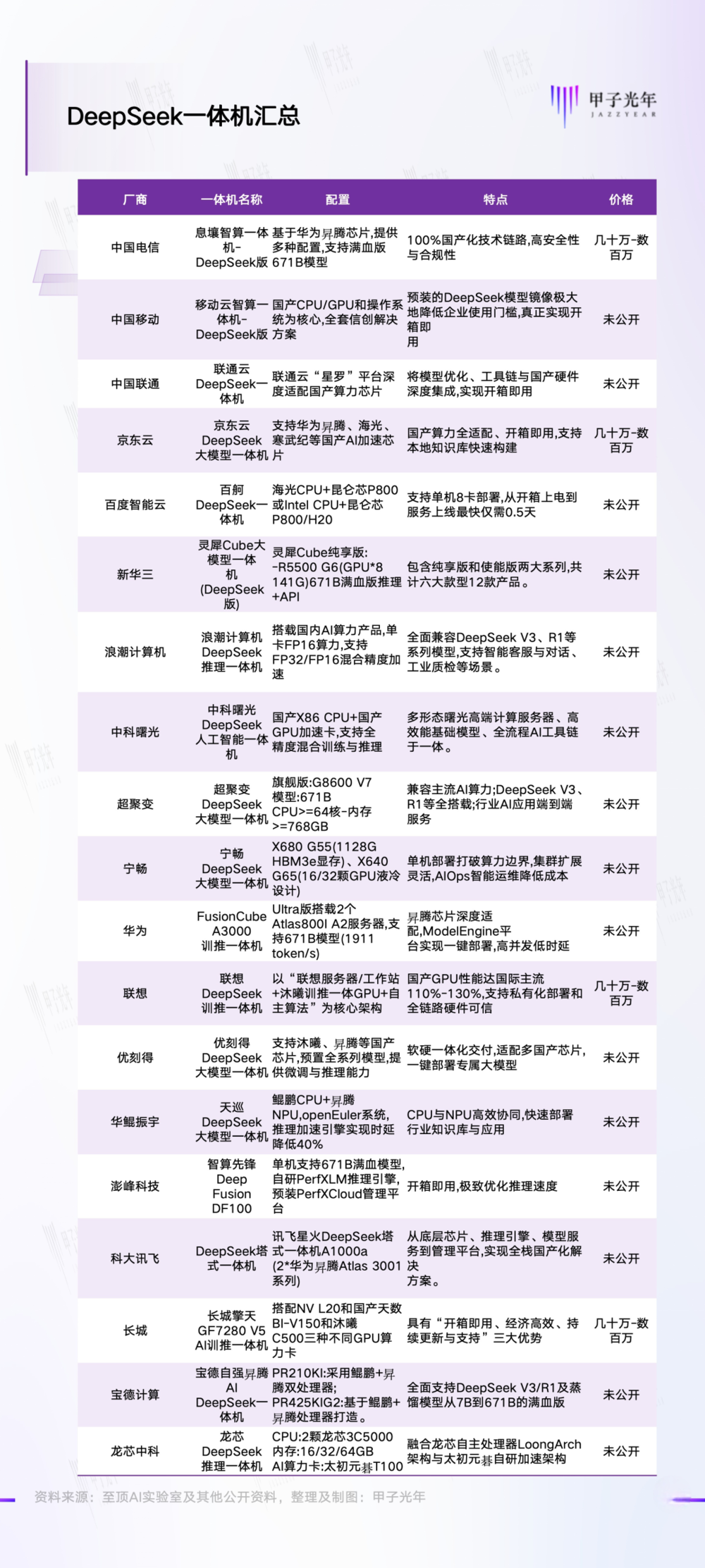
DeepSeek 一体机发布情况,制图:甲子光年
根据浙商证券研报,目前,已有 23% 的央企有大模型部署,未来大模型的普及率预计会进一步增加;而随着 DeepSeek 带动大模型的快速部署需求,一体机的部署占比有望持续增长,浙商证券预计,2025—2027 年,一体机采购量将分别达到 15、39、72 万台,DeepSeek 一体机在央国企的市场空间有望达到 1236、2937、5208 亿元。
二、央国企要国产,民企要 H20
那么,这些厂商推出的一体机都卖给谁了呢?
政府和央国企显然是这一波 DeepSeek 一体机上新潮的最大客户。
近年来,中国持续推进信创产业和国产替代战略,要求关键领域 (如政府、金融、能源等)优先采用国产技术,降低对外依赖。DeepSeek 作为本土 AI 企业,其产品天然符合这一政策导向。
加之政府和央国企涉及大量政务数据、民生数据和国家基础设施数据,对数据安全和隐私保护的要求极高,DeepSeek 一体机的本地化部署和封闭式架构,不仅能满足政府和央国企对数据和隐私的合规要求,而且开箱即用、无需雇佣庞大的运维团队,因此成为了政府和央国企的首选。
有数据统计,截至 2 月 21 日,已经有 45% 的央企完成了对 DeepSeek 模型的部署,而这其中不少企业都选择了一体机的方案。
从不到一个月的时间内,如此高比例的央企实现了对开源模型的快速覆盖,这一速度在过去是难以想象的。
除了政府和央国企,民营企业也是部署 DeepSeek 大模型的重要玩家。
由于百度、阿里等互联网巨头自己就是云服务商、自己就售卖一体机产品,因此购买一体机的多是有资金实力的大型民企中的个别业务部门,或者有数字化转型需求的中小民营企业。
「购买我们一体机的金融类客户比较多,因为一体机首先就主打线下私有化交互,而这些客户首先强调的就是数据不出域。除了金融类客户,政务类客户和之前的头部大 KA 也是购买一体机的主力客户。」 京东云 PaaS 业务部产品负责人贺皓告诉 「甲子光年」。
「甲子光年」 了解到,在打算购买一体机的企业中,大型央国企的预算较高,一般在 200 万-500 万之间;中小型政府机关、央国企和民营企业的比较容易批下来的预算一般在 100 万以内;而在这 100 万中,又根据预算金额的不同,分为 50 万-100 万、10 万-50 万、10 万以内三个区间。
目前,客户预算集中在 10 万-50 万的区间内,这与客户对部署大模型 「尝鲜」 的需求和企业的预算审批制度高度相关。
「有的部门,领导手里的权限就是 50 万,领导签个字这 50 万就能批出来,所以一体机厂商大部分也都是围绕这个价格来定价的。」 陈娇娇说。
而具体到模型的选择上,90% 以上的客户都在咨询满血版 DeepSeek 大模型的一体机部署方案。
「首先从实际效果来说,满血版肯定是最优的;其次,有一小部分客户有明确的业务使用场景,因此他们希望先部署满血版,有了满血版模型之后再去研究能对接什么样的应用场景。比如金融机构之前一直在做投研分析报告等东西,他们其实原来也是用大模型做,DeepSeek 出来之后,他们就想用满血版来看一下,验证一下 DeepSeek 满血版的性能和效果是不是更好。」 贺皓说。
尽管人人都想部署满血版,但不是人人都有实力买得起满血版。「甲子光年」 从各一体机厂商的市场和销售人员处了解到,在广大的中小企业客户中,成单量最高的是 70B 的模型。
预算有限肯定是首要原因。但这其中还有一个原因是,绝大多数企业还处于对大模型的 「试验」 和 「尝鲜」 阶段,70B 的模型(下文简称 70B)足以应对办公场景的需求。其中,知识库、办公助手、智能客服等是最为高频的应用场景。
「70B 是性价比最高的,企业如果直接部署了满血版,万一这个东西不好用,硬件成本怎么回收也是一个问题。而 70B 可以直接扩容到满血版(通过增加机器台数的方式)。」 潞晨科技市场经理赵一飞表示。
四通集团产品经理戴歧航也表示,部署满血版大模型的价格对绝大多数中小企业来说还是太高了:「70B 买我们的设备的话 20 万可以,671B 的话要 120 万以上。针对一般企业办公类的使用场景,70B 足够了。」
企业选择一体机,最看重的是其内置的GPU芯片。
由于 DeepSeek-R1 模型的推理只激活 671B 参数中的 37B 参数,降低了对算力的要求,但其大规模并行的架构对芯片的显存提出了更高的要求。因此算力被 「阉割」、但有着较大显存和带宽的 H20 成为了运行 DeepSeek 推理模型最有性价比的选择——两台 96G 版本的 8 卡 H20 一体机就能运行满血版大模型。
这也是 DeepSeek 模型火出圈后,H20 的市场行情从 「卖不出去」 转为 「供不应求」 的原因,一台 96G 版本 8 卡 H20 服务器的市场价格也从原来的 100 万上升到了 110 万左右。

英伟达部分显卡的参数规格,制图:甲子光年
2025 年 2 月,为了应对 DeepSeek 带来的大显存需求,英伟达 「趁热打铁」,推出了 H20 的升级版本——拥有 141G 显存的 H20。新升级的 H20 不仅显存容量更大了,而且显存带宽也从原来的 4TB/s 提升到了 4.8TB/s,能够实现更快的数据传输速度。
相较于原来 96G 显存版本的 8 卡 H20 一体机需要两台才能跑 DeepSeek 满血版大模型,141G 显存版本的 8 卡 H20 一体机只需要一台就能跑满血版,极大降低了企业的模型部署成本。搭载了 H20 芯片的 DeepSeek 一体机也成为了绝大多数有资金实力的民营企业部署满血版 DeepSeek 大模型的最优选择。
然而,由于目前 H20 141G 的版本刚刚推出、正在批量交付,市场上的现货并不多;加之是阉割版的芯片、央国企不允许购买,因此正式被投入到企业中使用的 141G 显存版 H20 一体机并不多,真正出货量较多的还是搭载了 H100、H200 等芯片的一体机。
此外,这波 DeepSeek 浪潮也带动了国产芯片的出货,和国产芯片一体机销量的增长。
正如前文所提,在国家政策的要求下,不少政府和央国企都需要在本地部署大模型,于是搭载了华为、摩尔线程、沐曦等国产 AI 芯片的 DeepSeek 一体机则成为了政府和央国企满足数据安全、高效算力和简易部署的第一选择。也因此,不少一体机厂家都在主推搭载了国产 AI 芯片的一体机,「单机跑满血版」 更是成为了一部分厂家的主打卖点。
目前,包括三大运营商和华为、浪潮信息、联想集团、京东云等在内,众多 IT 厂商都推出了包含国产芯片的一体机产品,比如联想联合沐曦发布了基于 DeepSeek 大模型的首个国产一体机解决方案;华为与中国移动、华鲲振宇、宝德、神州鲲泰、长江计算等 20 余家厂商合作推出了基于昇腾芯片的 DeepSeek 一体机,覆盖金融、医疗等领域;海光、壁仞、天数、摩尔线程、算能等国内芯片厂商也通过合作或自研的方式推出了自己的一体机产品。
但相较于英伟达的 H20,国产一体机并不是性价比最高的选择。
以满血版 DeepSeek 大模型的部署为例,目前市面上一台 141G 显存的 8 卡 H20 一体机的价格约为 140 万元,更高端一点的 8 卡 H200 一体机的价格约为 200 万元;而国产机方面,一台搭载了 8 卡昇腾 910B 的一体机价格约为 130 万元,如果是 64G 显存的训推卡部署满血版 DeepSeek 至少需要两台机器,如果是 32G 的推理卡则至少需要四台。
也就是说,如果选择昇腾卡来部署满血版 DeepSeek,那么至少需要花 260 万-520 万不等,性价比远不及英伟达的 140 万。
然而,即使性价比远不如英伟达,在国家的信创政策和安全性、隐私性等因素的考量下,大量政府、央国企和金融企业仍然选择购买国产芯片的一体机。
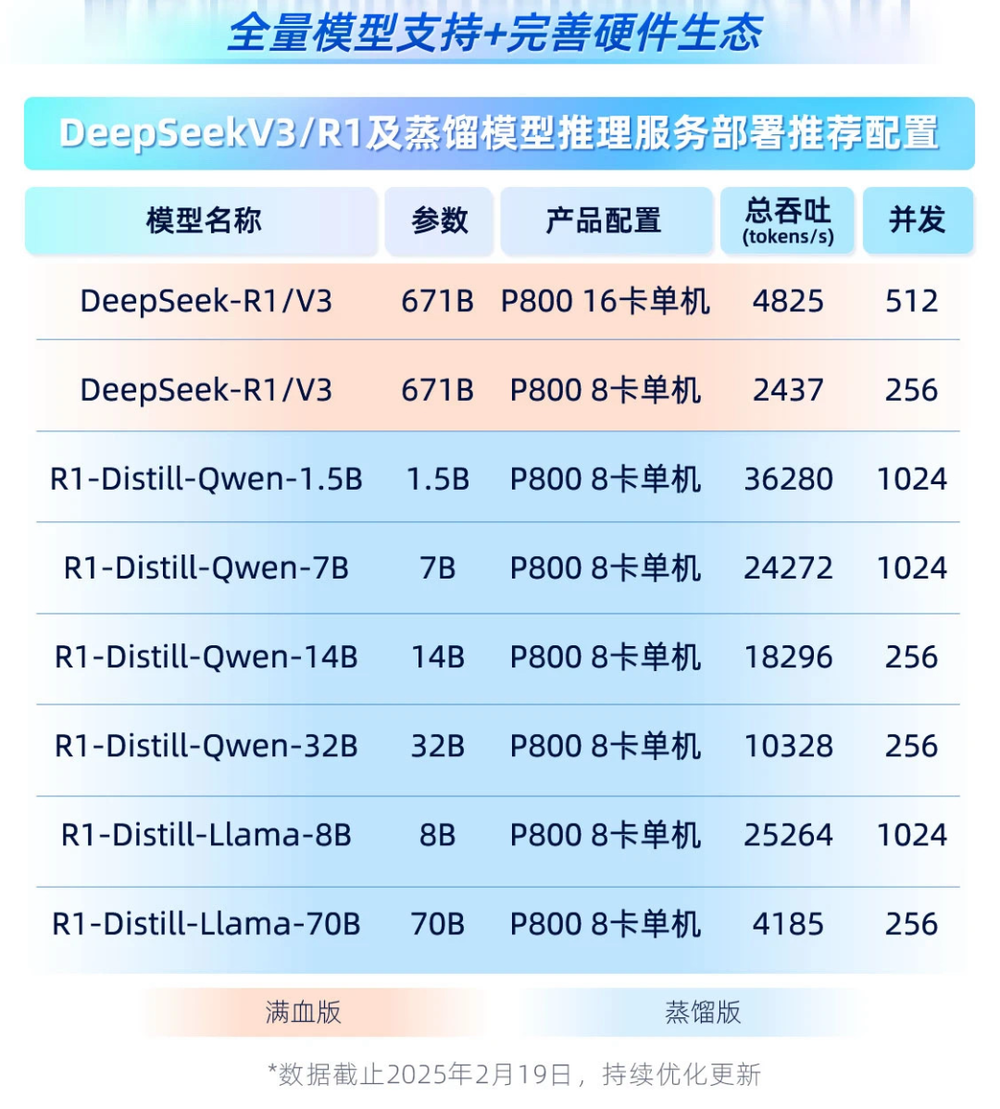
3 月 7 日,沐曦集成电路发布消息称,他们与联想集团合作的国产 DeepSeek 一体机累计发货量已经突破千台,配备沐曦国产 GPU 卡近万张,覆盖医疗、教育、制造等十余个核心行业;另据相关媒体报道,华为昇腾 DeepSeek 一体机今年一季度的销售任务已被提前完成。
最近也有昇腾相关专家对外公开表示,在国产卡一体机里,昇腾卡的占比达到了 70% 以上。同时,昇腾 GPU 的今年出货量在 75 万到 80 万张之间,其中 910B 约为 35 万张,910C 约为 40 万;而在需求结构上,地方算力中心 10 万张,运营商 20 万张,互联网企业 40-50 万张。这其中,一体机形式的约为 5-10 万张,以政企需求为主,已经快要接近智算中心对昇腾 GPU 的需求量。
而由于政企数字化市场容量巨大,且相对碎片化,不存在一家通吃的情况,因此短期内,国内的大小科技公司都有机会在 DeepSeek 一体机这个市场上赚到钱。这也是服务器、算力、软件、IT 系统集成等各行各业的科技公司都来掺和 「DeepSeek 一体机」 这件事的原因。
那么,国产一体机跑满血版大模型,究竟靠谱吗?
三、国产卡一体机跑满血版,靠谱吗?
衡量大模型推理性能的有两个指标,分别是系统吞吐(TPS,Tokens Per Second)和并发数(Concurrency)。其中,系统吞吐指的是单位时间内模型处理的 Token 数量,它直接影响实时交互场景的流畅性;而并发数则是模型同时处理多个请求的能力,它直接影响系统的扩展性。
如果要将衡量指标更进一步细化,那么可以再加上 TTFT(Time to First Token,生成首个 Token 所需时间)和 TPOT(Time Per Output Token,每生成一个 Token 所需的时间)。模型的整体推理延迟 (Latency)就可以根据这两个指标计算出来 (计算公式为:Latency=TTFT+TPOT×生成 Token 数)。
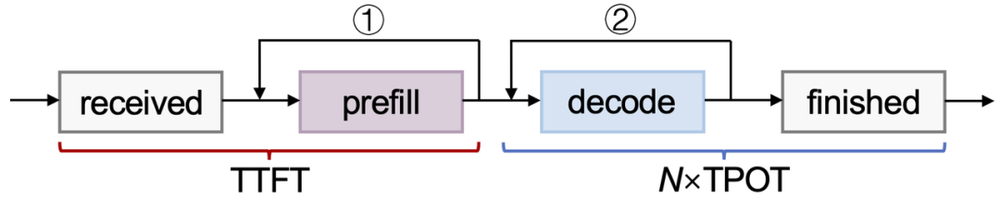
大模型推理服务流程,图片来源:无问芯穹
一般而言,TTFT 要小于 5 秒-10 秒,而在 1 秒-1.4 秒之间是大部分用户能够接受的延迟;而 20token/s 的每秒生成 Token 数能满足一个用户的正常阅读需求。
「甲子光年」 了解到,目前大部分国产芯片一体机跑 DeepSeek 满血版大模型的时间大概是 10 token/s,其中某国产芯片厂商在自己的文档中写道月底会将数据优化到 25Token/s。

而英伟达的数据是什么样呢?
某国产 AI Infra 厂商用 141G 显存的 8 卡 H20 一体机做了测试。通过硬件调优、算子优化、混合并行、多 token 预测等多方面的工程实践,在单路并发、268tokens 输入、2869tokens 输出的情况下,英伟达 8 卡 H20 一体机实现了单用户吞吐最高 32.9 tokens/s、平均 TTFT 191.72ms 的表现;
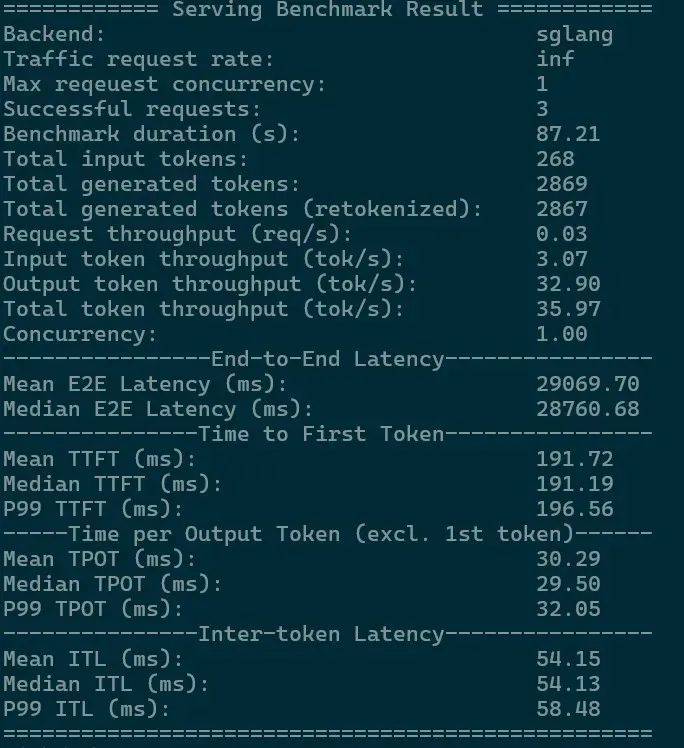
8 卡 141GH20 单路并发测试日志图片来源:公众号 IT 技术分享-老张
而在 1024 路并发、1000/1000 的输入/输出长度的情况下,英伟达 8 卡 H20 一体机实现了 3975.76 tokens/s 的总设备吞吐。
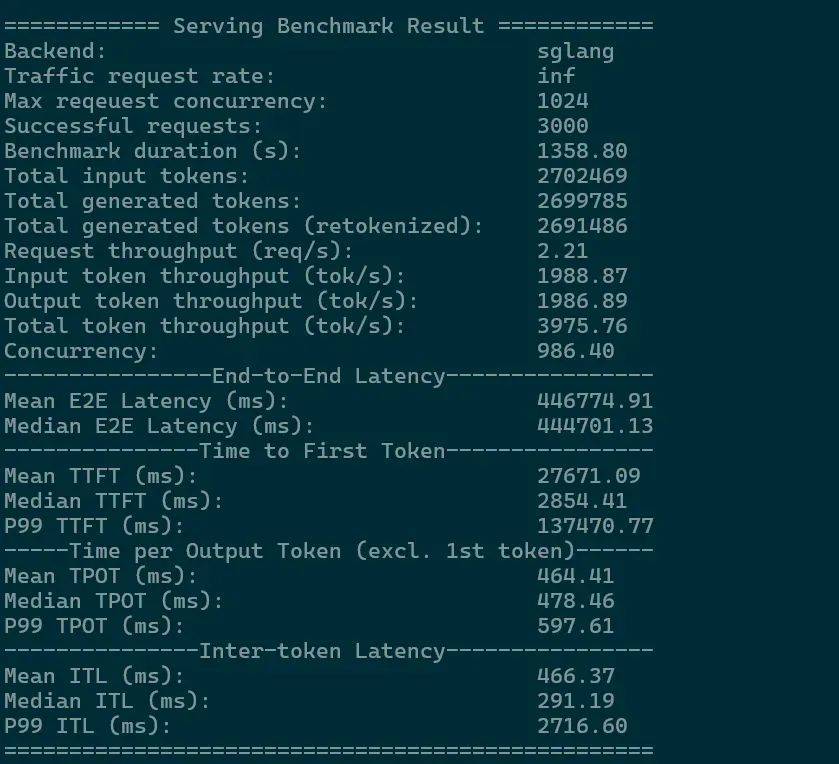
1024 路并发性能测试日志,图片来源:公众号 IT 技术分享-老张
也有工程师使用配置为八张 141G 显存的 H20GPU、两张英特尔至强 Platinum 8480+CPU、2T DDR5 内存和 3.84TB 的机器做了测试,结果显示,英伟达的 GPU 在单路并发、128tokens 输入、1024tokens 输出的情况下上跑出了平均用户吞吐率 23.68tokens/s、平均 TTFT 174.51ms 的成绩。
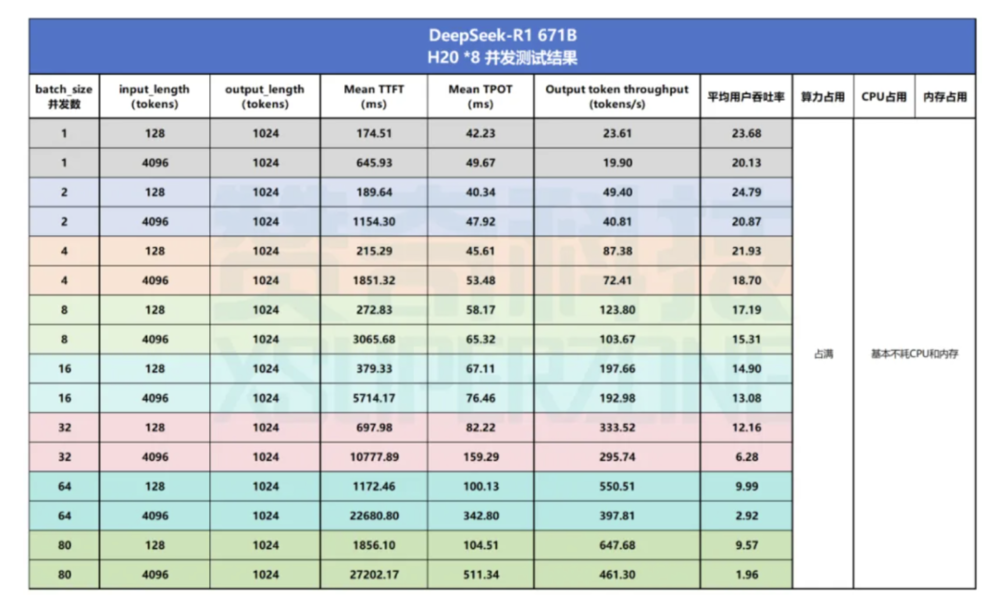
图片来源:赞奇科技
而在 NEOLINK LABS 的测试中,两台 8 卡 96G 显存的 H20 运行 DeepSeek-R1 满血版实现了高达 6279.08tokens/s 的峰值总吞吐。
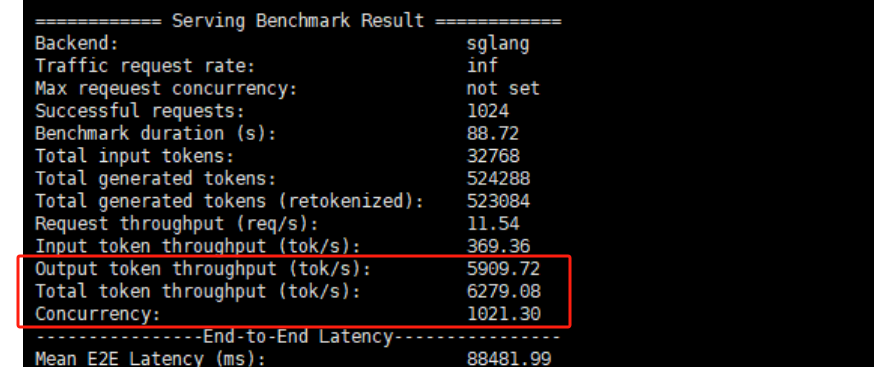
图片来源:公众号 「NEOLINK LABS」
可以看到,在系统吞吐和并发率两个指标上,国产AI芯片一体机严重落后于搭载了英伟达芯片的一体机。
尽管有些国产厂家声称自己家的一体机单机就能跑 DeepSeek 大模型、实现不输 2400tokens/s 的总吞吐 (这一数值约为 4 台 H800 一体机集群跑 DeepSeek 满血版的吞吐量),但这是在调整模型精度的情况下进行的。
图片来源:某厂商 DeepSeek 一体机宣传图
「有些厂家说自己单机就能跑 DeepSeek 满血版,吞吐和并发还很高,但他们跑的是量化版。很多厂商所谓的 『优化』 都是在降低模型智商的情况下进行的,很多国产卡一体机如果要在智商不下降的情况下运行满血版大模型,连单用户 10token/s 的吞吐都跑不到。」 陈娇娇说。
陈娇娇所说的 「量化版」,指的是在原生 FP8 数据精度的 671B 模型基础上,通过动态量化技术,将模型精度降低,提高模型吞吐,降低了所需硬件资源开销的模型。
目前市面上的满血版模型分为三种,分别是数据精度为 DeepSeek 原生的 FP8、显存占用 671G 的 「原生满血版」;数据精度为 BF16 或 FP16、显存需求未量化 1342G 的 「转译满血版」;数据精度为 INT8(Q8)、INT4(Q4,显存 335G)、Q2、Q1 的 「量化满血版」。只有原生满血版是最符合 DeepSeek 官方智商水平的模型,其他两个版本的模型都有一定程度的 「智商下降」。至于智商下降多少,则取决于技术团队做转译和量化时候的取舍和操作。
陈娇娇表示,还有些国产芯片一体机厂商根本不公布输入和输出长度,就直接说自己的产品跑 671B 大模型能输出多少 Token、达到多少并发。
「英伟达所有的结果都是有标准测试条件的,很多国产卡一体机厂商为了数据好看把测试条件全删了,然后说自己的数据比英伟达还好」,陈娇娇说,「我认为所有不公布输入、输出长度的性能测试都是耍流氓。」
某大厂高层也透露,自家公司出的一体机只是宣传的数据很好,但是实际跑起来的效果并不好,会出现各种毛病,时不时就要公司的业务人员前去维护。「就算跑的是量化版的模型,效果都很烂」。同时,该高管还告诉 「甲子光年」,截止到目前,这款单机能跑满血版的一体机销售额只有几千万,以 150 万/台的最高单价计算,出货量不过几十台。
为什么国产卡一体机跑满血版 DeepSeek 大模型的情况不如英伟达呢?
数据精度不匹配是第一个原因。DeepSeek 模型采用 FP8 混合精度训练,但目前公开市场上仅有三款国产 AI 芯片支持 FP8,分别是算能 SC1x、瀚博 VA1x 和摩尔线程 S5x,除此之外其他国产芯片均不支持 FP8。这也就造成了想要跑 DeepSeek 大模型,必须要将模型转译成 FP16 或 BF16 精度,或者通过动态量化技术将模型将模型变成量化版。转译成 FP16 或者 BF16 需要在原来基础上两倍的显存,而将模型变成量化版则需要损失一定的精度。
据陈娇娇表示,在能跑 FP8 的国产芯片中,其中有一家的表现尤为突出,因为他们在拿做过去成功的经验做 AI 芯片项目——立项的时候就押注 MoE 模型、大显存和低算力成本这三个点,而 DeepSeek 爆发后这三个点全部踩上了。
然而,由于被列入了实体清单,这家厂商只生产出来了少量的样品,尽管赌对了技术方向,但仍然无法大规模批量生产。
国产卡一体机的性能不足是第二个原因。而性能,是由内置 GPU 芯片的显存、制程和互联三个方面决定的:
目前国产 AI 芯片中,可以查询到的显存规格最大的芯片是昇腾 910B,训练卡拥有 64G 显存,推理卡拥有 32G 显存,而即使是 8 卡的 64G 显存规格昇腾芯片一体机,也无法满足满血版的显存要求。而英伟达 H20 普通版就有 96G 显存,升级版更是将显存提高到了 141G,单机就可运行满血版;
制程方面,国产 AI 芯片当前制程能力以 7-12 纳米为主,并在 28 纳米及以上成熟制程占据市场优势,但在 5 纳米及以下先进制程领域仍需突破技术和设备限制。而国外的 AI 芯片已经将制程突破到了 3 纳米,并且在 2025 年正式进入 2 纳米工艺元年;
互联方面,国产卡由于显存不足,仍然需要依靠多机互联来跑满血版大模型。目前英伟达的 NVLink、NVSwitch 互联带宽可达 900GB/s 以上,且支持大规模并行计算和低延迟通信;而国内仍然主要依赖 PCIe 4.0/5.0 或以太网互联,带宽和延迟均表现弱于 NVLink。即使有的国产芯片厂商会选择 InfiniBand(IB)或者高速以太网 RoCE 实现互联,但这些方案的通信延迟很大,这也会影响最终部署的效果。
尽管昆仑芯新推出的 P800 一体机据说单卡有 96G 的显存,可以实现单机跑满血版大模型,沐曦和摩尔线程也分别推出了时空互联 (推测 200–600GB/s)和 MT-Link 2.0(480GB/s)技术,但是国产一体机由于软件层面的优化不足,跑满血版的表现仍然欠佳。这也是国产卡一体机效果不如英伟达的第三个原因。
「市场上那么多做大模型一体机的,硬件扒开来看可能也就是那几个服务器厂商出的,大家差异化的点主要是在软件,包括底层架构的优化,推理引擎的优化,操作系统内核级的优化等,换句话说,大家都在比拼在同等硬件配置、同等规模参数的情况下,谁能提供提供更多的系统吞吐和并发。」 贺皓说。
而陈娇娇和他所在公司的的主营业务除了帮助政企客户做一体机的选型,还有一块很大的业务就是帮客户做一体机的部署和调优。
「一体机不同厂商之间其实就是在竞争两个点,一个点是对性能的优化,就是要在保证模型智商不下降、或者下降最小情况下的性能最优;第二个点则是应用做的好不好。」 陈娇娇说。
陈娇娇将当前市场上的一体机分为了 ABC 三类:
A 类是纯硬件,就是 AI 卡+机头的模式,更适合有开发能力的客户;
B 类是在硬件的基础上加上了模型和开发平台,如 Dify、DBgpt 等,更适合有实施能力的客户;
C 类是在 B 类的基础上叠加了一些应用作为整体产品输出,比如知识库等,更适合想要开箱即用的用户。
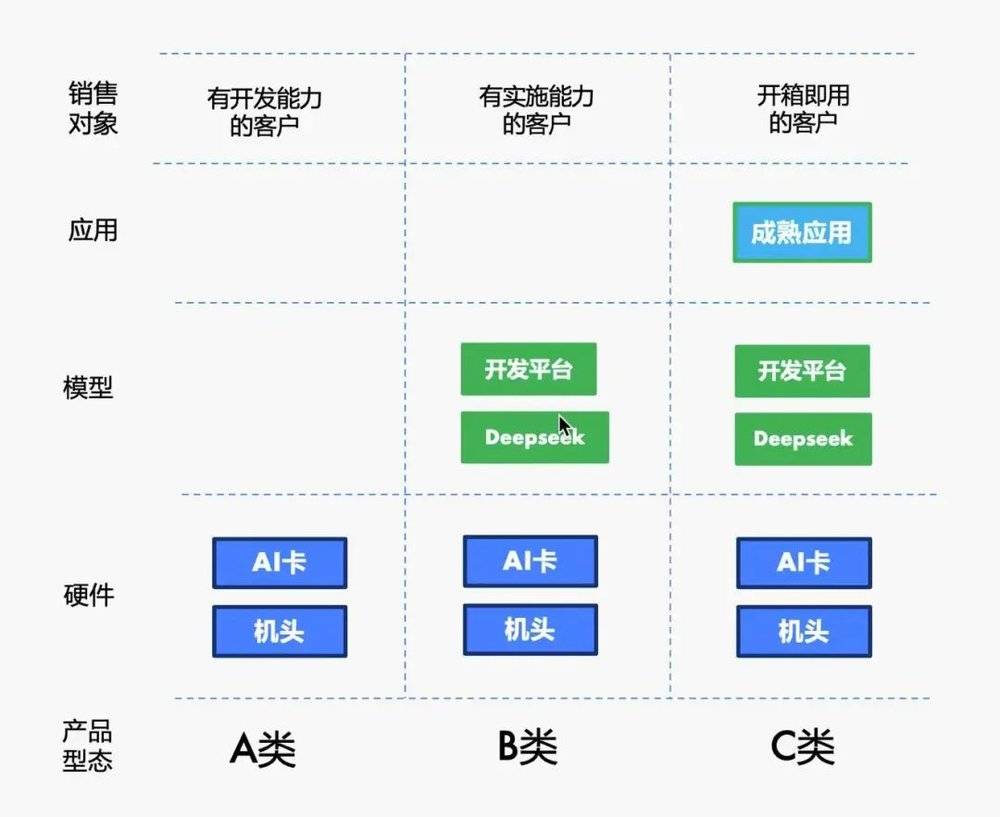
图片来源:公众号 「算力百科」
基于上述分类逻辑,陈娇娇也认同一体机之间的竞争主要是在软件。而由于一体机太火,市场上很多投机的人也进来做一体机了,但他们的软件调优能力是不足的,因此他们疯狂给那些预算有限的客户推销搭载了 32B、70B 等蒸馏版 DeepSeek 模型的一体机,销售出去后就不再提供后续的安装和维护服务。
「很多厂商可能把一体机定价定的比较低,比如卖到 30 万左右。但是在 30 万的硬件上,他们只能干 70B,干不了满血版。不是所有团队都有足够的软件能力驾驭 671B 大模型的,在十万或者几十万的硬件上,把 671B 满血版大模型跑到 10tokens/s 或者 15 tokens/s 以上是需要功底的,大部分人做不了。即使能勉强做满血版,并发也不太够,比如现在客户要求 20 个人、50 个人同时使用的话,就完成不了。于是他们跟客户说你用个 70B 吧,70B 的计算量小、并发高。看起来是甲方企业技术能力的问题,其实根本上还是乙方的问题。」 陈娇娇说。
陈娇娇表示,现在很多市场上做一体机的厂商专门给客户推 70B 或者更低参数的一体机,只强调并发量,不保证实际性能,至于能不能用的起来概不负责,等客户买单后就结束服务。一旦客户觉得不好用了,就让客户接着再买 「升级版」 的下一代产品。
「我还知道有些厂商,专门就给客户推 32B 的低价一体机,他们会说 『预算一定的情况下,我让合作伙伴多赚点钱不香吗』。」 陈娇娇说。
四、DeepSeek 最好的部署方式,并不是一体机
尽管目前几乎各家 IT 厂商都在做一体机,市场上也有价格不等、规格各异的一体机产品能满足客户各种各样的需求,但是 DeepSeek 大模型最好的部署方式并不是一体机。
这与 DeepSeek 的模型架构有关。
DeepSeek-R1 模型采用了 MoE 架构,每次只激活一堆专家里的少量专家。根据 DeepSeek 最新发布的文章,每层 256 个专家仅激活其中 8 个,相当于只激活了 671B 参数里的 37B 参数,因而极大降低了计算量。
但是,MoE 模型里那些未激活专家,虽然不消耗算力,但它们的参数量仍然要占用显存/内存,带来巨大的存储开销和调度复杂性。也就是说,必须要有很大的总 batch size,才能给每个专家提供足够的 expert batch size,从而实现更大的吞吐、更低的延迟。
运行数据精度为 FP8 的 671B 满血版模型需要多大的内存呢?根据行业内的计算公式,我们首先可以得出不同精度数据下,1B 参数内存的大小:
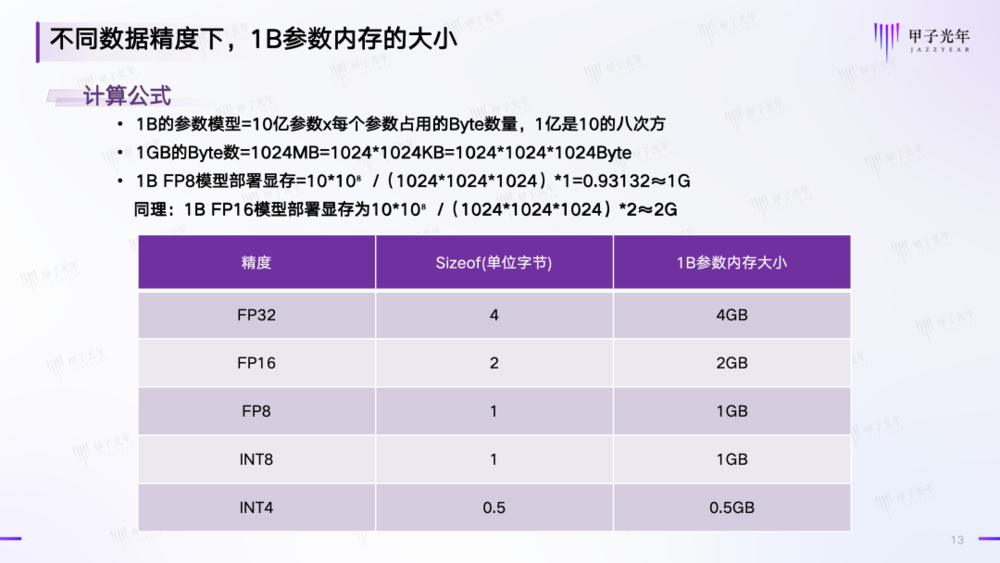
参考资料:IT 技术分享-老张制图:甲子光年
以 FP8 精度的满血版 DeepSeek-R1 671B 为例,假设 batch size=30,输入 Token 数=2048,输出 Token 数=2048,层数=61,hidden_size=7168;
按照 「DeepSeek 推理所需显存=模型参数部分+激活参数部分+KV Cache」 的公式计算,总的显存容量=671×1GB+37x1G+30×(2048+2048)×2×61×7168×1Bytes=671GB+100.08GB=808.08GB
此外,模型推理的上下文长度 (Context Length)不同会对 KV Cache 的显存占用影响很大,不同的厂商对显存大小的推荐也略有不同,下图是某大厂对 DeepSeek 不同模型参数量& 模型精度的显存推荐:
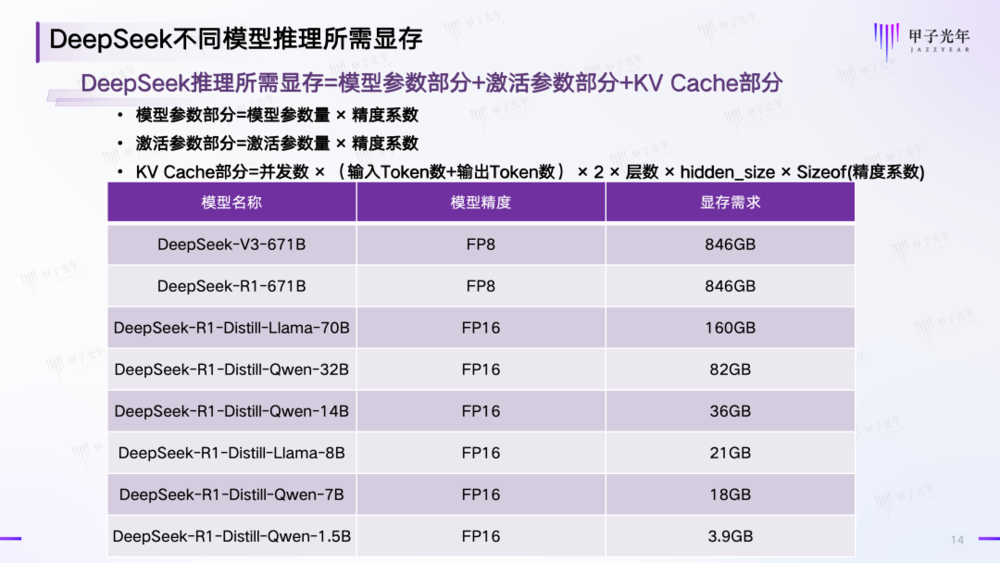
参考资料:IT 技术分享-老张,某大厂;制图:甲子光年
这也就意味着,如果要实现在一体机上运行满血版 DeepSeek 大模型,就必须把参数、配置拉满,起码显存要做到 808-846GB,机器才能装得下 6710 亿参数。然而,由于每次真正激活的参数只有 370 亿,剩余参数的存放对于显存、内存、硬盘来说是极大的浪费,因此一体机并不适合运行 DeepSeek 这种 MoE 模型,而是更适合那些非 MoE 的全参数激活模型。
DeepSeek 官方在其推理系统概览文章里也说,要实现更大的吞吐、更低的延迟就需要需要大规模的跨节点专家并行 (Expert Parallelism/EP)。也就是说,对企业来说,多机多卡的大规模的并行集群才是 DeepSeek 官方推荐的路线。

图片来源:DeepSeek 知乎官方账号
正因为这种采用了这种大规模并行架构,DeepSeek 才实现了令人惊讶的的单服务器平均推理性能。英伟达官方实测显示,DeepSeek-V3/R1 使用 H800 集群 (单节点 8 卡),在 FP8 混合精度下实现输入吞吐 73.7k tokens/s(含缓存命中)和输出吞吐 14.8k tokens/s。而国产一体机厂商们给出的性能指标,输出+输入的吞吐量总和最多也不过 4k tokens/s。
而在目前绝大多数中小企业预算有限、对采购的第一影响因素仍然是 「性价比」 的当下,一体机真实的销售情况也并未像市场中传言的那样火爆。
「甲子光年」 从多位一体机销售处了解到,今年 2 月到 3 月的一体机市场情况并不佳,大部分企业仍然以比价和观望为主,问的多、买的少;而即使有政策要求购买国产卡的一体机,但是部分央国企为了 「尝鲜」,仍然会选择在某一个部门部署一到两台英伟达芯片的一体机,对此监管部门也会睁一只眼闭一只眼。
「客户预算有限,都想先用我们的机器测一测性能,但是我们现在只有运营商这种比较大的客户才能给他们配机器测试一下,不然很多人测完了不买都是白嫖。」 超聚变销售经理孟令广表示。
或许也是看到了当前的一体机运行 DeepSeek 大模型的技术局限,近日,昇腾推出了大规模跨节点专家并行 (大 EP)集群推理方案,并和科大讯飞合作实现了基于昇腾算力的 8 机 64 卡 DeepSeek 大规模跨节点专家并行集群推理。这是继 DeepSeek 公布其 MoE 模型训练推理方案后,业界首个基于自研算力的全新解决方案。
昇腾大 EP 方案采用了 MoE 负载均衡、PD 分离部署、双流/多维混合并行、MLAPO 融合算子、MTP(多 Token 预测)等技术,实现了 MoE 模型专家之间的负载均衡——专家数据交换效率提升 40%,降低跨机流量 60%,卡间负载差异小于 10%,集群吞吐提升 30%;此外,推理集群的性能和吞吐量也得以提升——单卡静态内存占用缩减至双机部署的 1/4,效率提升 75%,专家计算密度增加 4 倍,推理吞吐提升 3.2 倍,端到端时延降低 50%。
紧随 DeepSeek 的 「号召」,升级后的昇腾大 EP 方案,可支持从几十卡到几千卡甚至更大规模的推理集群。而企业之前采购的一体机,也可以通过软件升级,扩展为大 EP 的推理方案。
「甲子光年」 从某大厂高管处获悉,目前大部分企业都已经结束了 「尝鲜」,正式进入了采购和部署阶段,而部分企业的采购决策也从开箱即用的 DeepSeek 一体机,转向了可支撑高并发、低时延的大规模专家并行(EP)推理集群。这也是 DeepSeek 开源自己的技术方案后给市场带来的改变。
但是,这并不意味着一体机就是一个很差的产品形态。对于预算有限或者业务场景对 AI 需求不大的企业,一体机仍然是他们尝试 AI、初步探索大模型赋能业务场景的最佳选择。
对这些企业来说,无论是搭载了蒸馏版 DeepSeek 模型的一体机,还是搭载了非 MoE 架构的小体积新模型的一体机,都足以应对现有业务的 AI 部署需求。而在 DeepSeek R2 推出之后,还将会有更多公司基于新的模型推出一体机或其他的硬件产品,届时再部署或许也将能实现更高的投入产出比。
无论算力产品形态如何演变,长期看,唯有国产芯片在算力密度、互联技术和开源生态上实现突破,一体机才能越来越才能真正打破 「性能妥协」 与 「国产合规」 的二律背反,让 DeepSeek 的 「中国式爆发」 不止于热闹,而是沉淀为一场扎实的产业进化。
本文来自微信公众号:甲子光年 (ID:jazzyear),作者:王艺,编辑:栗子
